重磅喜讯刷屏全球!6月24日,《纽约时报》中文网官宣重磅消息:中国正式从美国手中夺回全球超算桂冠!坐落于深圳的国产大型计算系统“灵晟”,成功登顶全球最快超算,测试速度比美国称霸多年的“酋长岩”系统还要快20%以上!这也是中国近十年来,首次重返全球超算排行榜榜首。
此次登顶含金量十足,灵晟搭载全栈国产芯片,采用纯CPU超智融合架构,是西方技术封锁倒逼下,中国自主研发、工程集成的硬核突破,全程自主可控,彻底打破美国垄断!
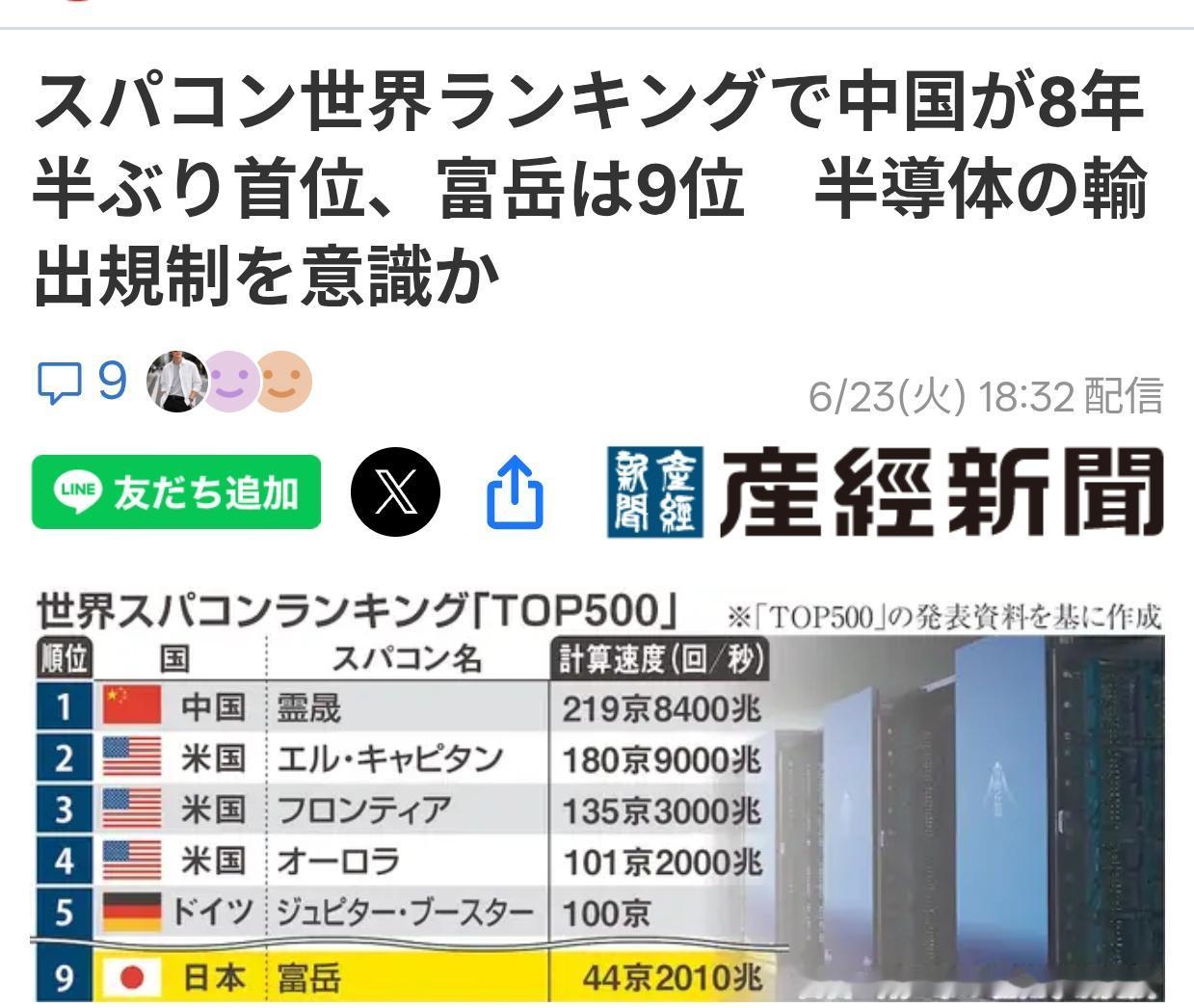
这个消息刚出来,国外科技圈都炸了。要知道,过去十年全球超算TOP500榜单里,前几名基本被美国、日本的机型霸占,尤其是美国的“酋长岩”,自2024年11月登顶后就没挪过窝。谁也没想到,这次半路杀出个“灵晟”,不仅直接超车,还创下了个世界纪录——全球首台持续性能突破2EFlops的超算系统,实测速度达到2.19EFlops,换算成大白话就是每秒能完成219亿亿次运算。
可能有人对这个数字没概念,咱们算笔直观的账。如果让全球80亿人同时用计算器做题,每秒算一次,要凑够“灵晟”一秒的计算量,得连续算8.6亿年。要是换成一台顶配家用电脑,得219万台同时满负荷运行,才能勉强赶上它的速度。更牛的是,它还顺带拿下了HPCG榜单第一,这个榜单比TOP500更考验超算的综合实力,相当于既拿了短跑冠军,长跑成绩也稳居第一。
说到这里,必须提“灵晟”最颠覆的地方——它没用到一块GPU。现在全球顶尖超算,不管是美国的“酋长岩”,还是欧洲的E级超算,清一色靠英伟达或AMD的GPU撑算力,TOP500里81%的机型都离不开英伟达技术。但“灵晟”偏不走寻常路,用纯CPU架构就实现了反超,这在行业里简直是“异类”操作。
背后的核心秘密,是咱们自研的LX2芯片。这颗芯片基于ARM v9指令集,每颗集成304个核心,整机一共装了近1400万个核心。更绝的是,研发团队把AI矩阵加速单元直接嵌进了CPU里,既能搞定传统科学计算,又能支撑AI训练,相当于让一个“全能选手”同时兼顾了两项专长。搭配上国产HBM高带宽内存,内存带宽直接提升10倍,数据传输速度比传统超算快了不止一个档次。
除了芯片,整个系统从里到外都是“中国造”。网络用的是自主设计的“灵启”高速互连技术,节点间带宽能达到1.6Tb/s,支持10万节点的超大规模组网;存储采用分层架构,能轻松扩展到E级规模;就连操作系统都是国产的麒麟系统,再加上全栈自研的软件,真正实现了100%自主可控。
更让人惊喜的是它的节能表现。“灵晟”首创了全液冷散热机柜,整机能效比达到51GFlops/W,在Green500能效榜上排到第50位。要知道,超算一直是“电老虎”,能在2.19EFlops的高性能下做到这么节能,相当于既跑得快,又不费油,这背后的工程设计功力可见一斑。
其实这背后,藏着一段挺憋屈的往事。还记得2017年“神威·太湖之光”登顶后,美国就加紧了技术封锁。2018年以后,不仅禁止向中国超算中心出售高端芯片,还把一批科技实体列入“实体清单”,到2025年,被制裁的中国科技企业已经达到2021年的三倍。之前“天河二号”因为用了英特尔芯片,想升级都被卡脖子,这也让咱们彻底明白,关键核心技术买不来、讨不来。
这次“灵晟”的总设计师卢宇彤,早在2013年就带着“天河二号”六次站上世界之巅。时隔十一年再登领奖台,她带领团队走出了一条完全自主的路。没有GPU可用,就深耕CPU架构创新;被限制技术交流,就自己搭建软件生态;从芯片设计到机柜散热,每个环节都亲自攻关,这才有了今天的突破。图灵奖得主Jack Dongarra都忍不住点赞,说“灵晟”为全球超算指出了新方向。
现在“灵晟”已经开始干活了,而且一上手就是硬骨头。在气象领域,它能精准模拟台风路径,为防灾减灾争取时间;在医药研发上,它能快速筛选抗癌药物分子,把原本需要几年的研发周期缩短到几个月;在新材料领域,它能模拟材料微观结构,助力高端制造升级;甚至在大模型训练、脑科学研究这些前沿领域,它都能提供澎湃算力。
说到底,“灵晟”登顶不只是一个排名的变化,更是中国科技突围的缩影。过去我们总被说“缺芯少魂”,超算领域更是被西方技术围堵了十几年。但这次我们用纯CPU架构实现反超,证明了不用跟着别人的路线走,也能走出自己的康庄大道。
更重要的是,算力已经成为数字时代的核心生产力,就像工业时代的电力一样。“灵晟”的出现,意味着咱们在气象、医药、航天、AI这些关键领域,不用再看别人脸色要算力,不用怕被卡脖子。以后咱们搞科研、做产业,都能有自己的“算力底气”。
九年磨一剑,从“太湖之光”到“灵晟”,中国超算走的每一步都不容易。但正是这种倒逼出来的自主创新,让我们在关键技术领域越走越稳。