这项由卡内基梅隆大学主导的研究于2026年6月以预印本形式发布,论文编号为arXiv:2606.16748,有兴趣深入了解的读者可通过该编号查询完整论文。
你有没有想过,如果给你配一个AI助手,让它帮你管理所有的网上账户——查查上个月的银行账单、帮你重新预订被取消的餐厅、把你惯常叫的外卖套餐发给朋友、再顺手把日历上的会议调到下周——它究竟能做得多好?这不是科幻电影里的场景,而是越来越多科技公司正在推向市场的产品方向。然而,在"AI个人助手"这个概念被炒得火热的今天,一个关键问题却鲜少被人正视:我们到底有没有一把靠谱的尺子,来衡量这些助手的真实水平?
卡内基梅隆大学的研究团队发现,现有的所有测试方案都有一个共同的致命缺陷:它们测试的都是"无主"的电脑。就像让一个厨师在一个空厨房里展示厨艺——没有食材、没有惯用锅具、没有家里常备的调料,测出来的成绩根本不能反映他在自家厨房里能端出什么菜。真实的个人电脑上,堆积着几年的邮件往来、消费记录、日程习惯、聊天记录……这些"个人痕迹"才是一个AI助手真正需要读懂并驾驭的东西。
正是为了填补这个空白,这支团队构建了一个名为MYPCBENCH的测试平台——一台在虚拟机里运行的完整Linux桌面,上面住着一个有血有肉的"数字人":Michael Scott,《办公室》美剧里那个Scranton纸业公司的区域经理。这台电脑不是空的,它装满了Michael的生活:1812条银行交易记录、2398封电子邮件、679个日历事件、2526条聊天消息、402个外卖订单,以及超过1万条浏览历史……这篇文章要讲的,就是这个"数字考场"是如何搭建的,测了什么,又测出了什么让人深思的结果。
一、为什么现有的测试方法都在考"空壳电脑"
要理解这项研究的价值,先得明白一件事:为什么在MYPCBENCH之前,所有的AI助手测试平台都回避了"个人数据"这个核心问题?
原因其实很现实。测试AI助手需要一个可以反复重置、结果可以被精确判定的环境。如果测试环境里包含真实用户的账号和数据,那么每次测试结果都会不同,也会引发严重的隐私问题。所以,大多数测试平台选择了一个折中方案:搭建几个"模拟网站"(比如模拟购物平台、模拟邮件系统),往里面填入极少量的测试数据,然后让AI完成一些明确指定的操作任务,比如"在这个购物网站上找到红色的T恤并加入购物车"。
这种测试思路本身没有错,它成功催生了WebArena、OSWorld等一批有影响力的基准测试工具。但它的局限性也非常明显:这些任务几乎都是"单点操作",任务里会直接告诉AI要打开哪个应用、做什么操作,不需要AI自己去判断"这件事应该从哪里入手"、"这条信息在哪个应用里找"。更关键的是,这些测试环境里根本没有用户的历史数据。你问AI"我平时每周五都在哪家餐厅订外卖",它没有任何数据可以查,这个问题根本无法在测试里出现。
然而,真实用户对AI助手的期待恰恰就是这些"需要了解我"的任务。卡内基梅隆大学的研究团队把这个现象称为"个性化鸿沟"——测试环境和真实使用场景之间的巨大断层。他们翻阅了OpenClaw社区(一个专门讨论AI个人助手使用体验的大型Discord社群)里2749个真实用户需求,发现绝大多数真实请求都需要AI跨越多个应用、调取历史数据、理解用户的个人习惯。这些需求在现有测试里完全缺席。
二、搭建一个"有人住过"的数字家园
MYPCBENCH的核心创意,是用一个虚构人物的完整生活来填满一台电脑,让测试环境真正"有主"。
选择Michael Scott作为这台电脑的主人,是一个既聪明又有趣的决定。Michael是《办公室》这部美剧里深入人心的角色,他的人际关系网络、工作背景、生活习惯都已经在剧中有充分描绘。这意味着研究团队可以用AI编程助手大规模生成与这个角色高度吻合的数据——Michael会给同事Pam发Zelle转账,会在HooliChat(类似WhatsApp)上找Jim咨询约会建议,会定期预订Cooper's Seafood House的晚餐,会坐Dinoco Airlines(类似达美航空)去费城出差。这些数据不是随机生成的,而是彼此关联、互相呼应的。
研究团队用一个JSON格式的"人物档案"来定义Michael的完整个人信息,这份档案涵盖了他的身份信息、财务状况、社交网络、旅行记录、工作项目、消费习惯、浏览偏好……然后,一套确定性的自动化程序把这份档案"翻译"成17个模拟网站里的真实数据,以及Firefox浏览器的历史记录、书签和登录状态,还有桌面文件夹里的会议记录、差旅报销单、机票PDF等文件。
这17个模拟网站覆盖了一个现代人数字生活的主要场景,每一个都对应一个真实的知名平台。比如,Gringotts对应Chase银行,支持账户查询、转账、Zelle付款和账单下载;Dinoco Airlines对应达美航空,能生成带二维码的登机牌;TableFind对应OpenTable餐厅预订,预先计算了31天内4128个可用时段;eTaxi对应Uber,能根据真实地图路线规划行程;HooliMail对应Gmail;HooliCalendar对应Google日历;HangryDash对应DoorDash外卖……整个环境里,17个应用共有226张数据库表,约42000行用户可见的状态数据。
最让这个测试环境与众不同的设计,是"跨应用一致性"。Michael的每一次生活事件,都会在所有相关的应用里留下痕迹。比如,他有一次去费城的出差之旅,会同时在Cheskepdia(类似Airbnb)里留下住宿预订记录、在Gringotts里留下两笔信用卡消费、在HooliCalendar里留下日程块、在Dinoco里留下两张登机牌、在HooliMail里留下三封差旅文件夹里的邮件,以及在HooliChat里留下提到这次出行的聊天记录。这种关联性正是真实个人电脑的本质——一件事情发生了,它的痕迹会散落在你数字生活的各个角落。
三、184道题,考的都是"了解你"的能力
测试环境有了,下一步是出题。研究团队从OpenClaw社区筛选出的2749个真实需求中,剔除了近似重复的、在虚拟机里根本无法实现的(比如"给我妈打电话"),以及需要用到17个应用之外的工具的,最终提炼出184道测试题,每道题都把原始需求里的人名、地名、日期改成了Michael Scott的真实数据版本。
这184道题按照"考察的核心能力"被分成六大类型,每个类型都测试AI助手的不同侧面。
最基础的一类叫做"有界操作",共64道题,占总数的35%。这类题要求AI完成一个具体的写入操作,比如"给Pam发100美元的Zelle转账,备注上我们上周末的饭钱,但先去HooliChat确认Pam Beesly在我的联系人里"。这类题相当于考察AI能不能准确理解指令、找到正确的入口、按步骤完成操作。
第二类叫"多步骤编排",共48道题,占26%。这类题要求AI跨越多个应用,同时完成读取信息和写入操作,并且通常要生成一个"成果物"。典型的题目是:"威胁级午夜粉丝俱乐部沉寂已久。去看看群聊,翻翻LockedIn上Dunder Mifflin的同事,给他们起草一封邀请邮件,再在日历上订一个下个月的观影派对。"这道题需要AI同时操作HooliChat、LockedIn、HooliMail和HooliCalendar四个应用,而且每一步的内容都依赖于上一步的发现。
第三类是"跨来源核对",共25道题。这类题要求AI把多个应用里的信息拼在一起,回答一个涉及数量或可行性的问题,比如:"我的牙买加之旅和巴巴多斯之旅相差四周。考虑我的信用卡余额,我真的两个都能订得起吗,还是会刷爆?"AI需要同时查询旅行预订记录和银行账户信息才能给出有意义的答案。
第四类是"汇总与报告",共23道题。AI需要从大量记录里计算统计信息,并把结果输出到LibreOffice文档里,比如:"我每个月通过Zelle发了多少钱,都给谁了?查最近两个完整的日历月,把收款人按金额排名,做成一张LibreOffice Calc表格。"
第五类是"个人信息查询",共13道题,相对简单,只需要找到一个具体的数据,比如:"我在Dinoco Airlines的FlyMiles忠诚度等级是什么,账户里还有多少里程?"
第六类是"模式推断",共11道题,也是最有趣的一类——AI需要从历史数据里归纳出一个从未被明确记录过的规律,比如:"我在外卖上一般给多少小费,绝对金额和百分比各是多少?我想设一个智能默认值,省得每次下单都要想。"这类题没有一个现成的答案可以直接查,AI必须翻阅所有的外卖订单记录,自己计算出规律。
在这184道题里,有68%需要同时操作多个应用,有40%需要跨越至少两个不同的互联网领域(比如同时涉及金融和餐饮)。任务跨越的应用数量从1个到19个不等——是的,最复杂的任务需要AI在19个不同的应用之间穿梭协调。
四、六位"考生"的成绩单
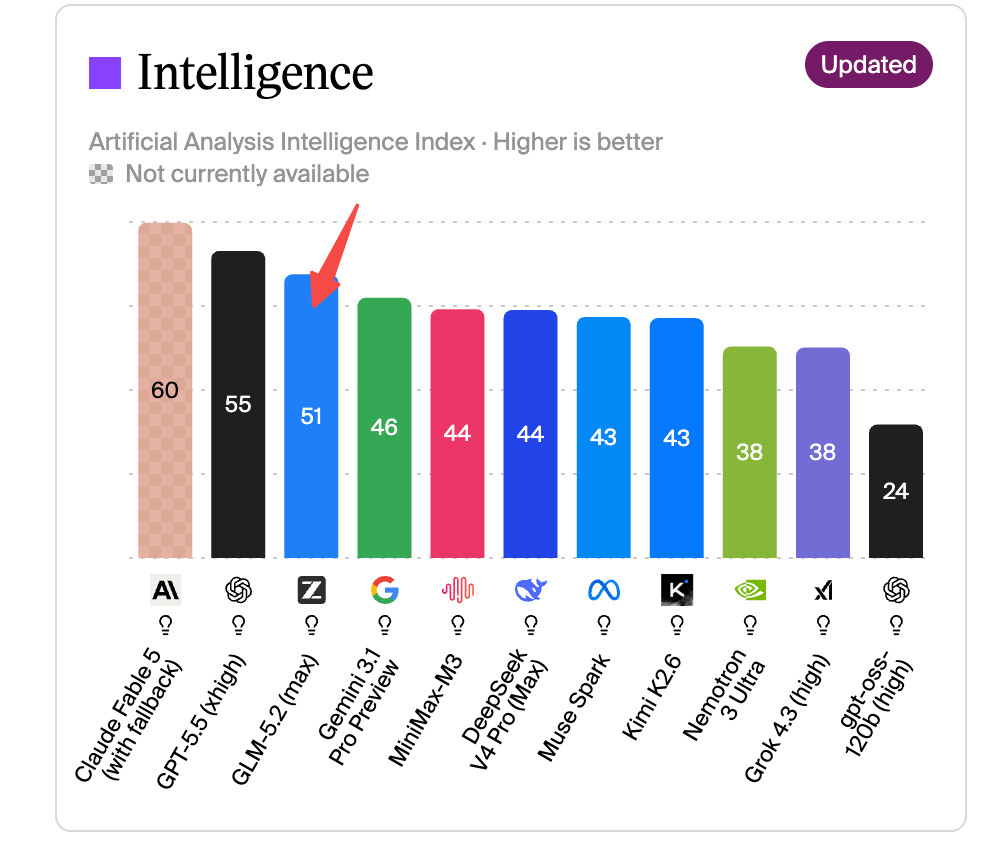
研究团队让六个不同的AI模型在MYPCBENCH上完成全部184道题,这六个模型分别是:来自Anthropic公司的Claude Opus 4.6和Claude Sonnet 4.6、来自OpenAI的GPT-5.5和GPT-5.4 mini,以及两个开源模型Qwen 3.5 35B-A3B和Qwen 3.5 9B。
每个模型都被限定使用相同的工具组合:一个截图+鼠标键盘操作的"电脑工具",加上一个可以运行命令行的"bash工具"。每道题最多给100轮对话(每轮AI看一次截图、决定一个操作)。
成绩的核心衡量指标叫"完美率"——在一道题的所有评分项(称为"评分标准",每道题平均有6.5条,总计1191条)全部通过的情况下,才算这道题"完美完成"。此外还有一个"评分分数",允许部分得分,以及一个衡量每一步操作效率的"轨迹效率"。
成绩出来之后,差距触目惊心。Claude Opus 4.6以55.4%的完美率排名第一,是唯一一个超过50%的模型。紧随其后的Claude Sonnet 4.6完美率为39.1%,GPT-5.5为29.3%,GPT-5.4 mini为19.0%。两个开源模型的差距更大:Qwen 3.5 35B-A3B仅有7.6%,而Qwen 3.5 9B只有可怜的2.7%。
换句话说,即便是目前最强的商业AI模型,也有将近一半的个人助手任务无法完美完成。
从轨迹效率来看,Claude Opus 4.6每走一步能获得3.61%的评分进展,而Qwen 3.5 9B每走一步只有0.65%的进展——前者的效率是后者的5倍多。更有意思的是,步数多不等于效率高。Claude Sonnet 4.6平均走45.8步,效率为3.03;而Qwen 3.5 9B平均走69.2步,效率却只有0.65。多走的那些步,大多是在原地打转或者走弯路。
五、成绩背后的规律:哪些任务最难,哪些模型最容易"跑偏"
把成绩按任务类型和任务复杂度拆开来看,会发现更多有趣的规律。
在六种任务类型中,"个人信息查询"是所有模型表现最好的,因为它只需要在单个应用里找到一个现成的答案。而"多步骤编排"和"汇总与报告"是最难的,这两类任务需要AI同时在多个应用间协调、积累大量中间状态,对记忆能力和规划能力要求极高。在这两类任务上,GPT系列和两个Qwen模型的完美率都不超过16%,而Qwen 3.5 9B则干脆在所有需要推理分析的任务类型上完美率为零。
在"模式推断"这个类型上,各模型的差距尤其巨大。Claude Opus 4.6的完美率高达82%,GPT-5.5为45%,而其他模型都在10%以下。这类任务之所以难,是因为答案不是一个现成的数字,而是需要AI自己从数十条甚至数百条历史记录里归纳出一个规律——这考验的是真正的"理解",而非"检索"。
当任务涉及的应用数量增加时,所有模型的成绩都会下滑,但下滑的幅度差异极大。从单应用任务到7个以上应用的任务,Claude Opus 4.6的完美率从66%跌到36%,Claude Sonnet 4.6从46%跌到14%,而GPT-5.4 mini、Qwen 3.5 35B-A3B和Qwen 3.5 9B在7个以上应用的任务上完美率全部跌到0%,GPT-5.5也仅有4.5%的完美率。这意味着,在最能体现"个人助手"价值的那类复杂跨应用任务上,除了Claude两个版本之外,其他所有模型几乎都是完全失效的状态。
研究团队还分析了所有失败的评分项,把失败原因归纳成五种模式。最常见的是"过早结束"——AI在任务还没真正完成的时候就宣告"完成了",这种情况出现了354次,主要是GPT系列的问题(GPT系列在这一项上的错误次数是Claude系列的6倍多)。第二常见的是"跳过必要应用"——在需要操作多个应用的任务里,AI在打开部分应用后就停下来了,忽略了其他必要的应用,这种情况出现了323次。第三是"被界面错误卡住"——AI遇到验证码、加载慢、弹窗等问题后直接放弃,而不是想办法绕过,出现了129次。第四是"不完整的成果物"——AI打开了LibreOffice表格但忘记保存,或者文档内容不完整,出现47次。第五是"捏造用户数据"——AI自己编了一个数值而不是从数据库里查询,出现31次,这个问题在Qwen系列里最严重。
Claude系列有一个独特的失败模式,研究团队称之为"控制台脚本捷径"。Claude很聪明,它会直接用命令行工具(curl命令)去调用网站的后台接口读取数据,绕开用户界面。当任务只是"查询一个数值"时,这种方法是有效的。但当任务要求AI在用户界面上完成一个可见的操作(比如拖动一张卡片、从菜单里保存文件)时,Claude通过命令行读取了数据、在文字回复里报告了答案,却没有在界面上执行任何操作——评分标准需要的是"界面上的可见变化",所以即便答案是对的,也会被判定为失败。
六、一个"完美完成"的任务长什么样
为了让人直观感受这个测试有多难,研究团队展示了Claude Opus 4.6在一道复杂任务上的完整轨迹:任务标题是"Dundies生命周期计划",要求AI完成一项完整的活动筹备工作,需要同时操作10个不同的应用,共走了99步,最终所有9条评分标准全部通过。
具体来说,AI需要先打开一份分类文档读取Dundies奖项信息,然后在Cheskepdia(Airbnb)上搜索并筛选出至少两个合适的活动场地,再去HangryDash上考察餐饮选项,接着在HooliMail里给5位相关人员发送"预留日期"邮件,在HooliChat上发布协调消息,在HooliCalendar上为这一天添加日程,在SprintBoard(项目管理工具)上建立至少5个任务,最后在LockedIn上发布一条活动预告吸引职业网络。整个过程中,AI需要在不同应用之间来回切换,把在一个应用里找到的信息用在另一个应用的操作里,同时确保所有修改在重置测试环境后仍然持久存在——这最后一条是为了验证AI真的做了持久化的操作,而不只是临时填写了表单。
这样的任务,放在一个真实用户面前,大概需要半天时间、在七八个网页之间来回切换才能完成。Claude Opus 4.6在99步之内把它完美解决,确实令人印象深刻。但同样引人注意的是,即便是这个最强的模型,在全部184道题里,也有将近45%没能达到"完美完成"的标准。
---
说到底,MYPCBENCH这项研究揭示的核心矛盾是:市场上正在兴起的AI个人助手产品,和评价这些产品好坏的测试工具之间,存在一道巨大的鸿沟。现有的测试工具考察的是在空壳电脑上的操作能力,而真实的个人助手需要的是理解"这台电脑的主人是谁"——他的习惯、他的历史、他的圈子。这两种能力根本就不是同一回事。
这项研究还有一个耐人寻味的细节:在相同的工具条件下,不同家族的AI模型会用截然不同的方式"出错"。GPT系列太急于宣告完成,Claude系列太热衷于走命令行捷径,Qwen系列则要么会编造数据、要么在复杂工具组合下直接崩溃。这种"各有各的毛病",对于想要改进AI助手的开发者来说,其实是非常有价值的具体方向。
当然,这项研究本身也有明确的局限性:整个测试环境只围绕一个虚构人物搭建,没有考察AI助手在面对不同文化背景、不同使用习惯的用户时的表现差异。而且,能在一个精心搭建的测试环境里完美执行操作,和真正在真实用户的真实账户上安全可靠地工作,仍然是两回事——研究团队也明确强调,在MYPCBENCH上的成绩绝不应该被解读为可以在真实账户上部署的通行证。
值得思考的是:如果连最强的商业AI模型都只能完美完成一半的个人助手任务,那么现在市面上那些声称"帮你管理数字生活"的产品,究竟在多大程度上是真正的个人助手,又在多大程度上只是一个操作流畅的演示Demo?这个问题,也许比测试结果本身更值得我们认真对待。
有兴趣进一步了解这项研究的读者,可以通过arXiv:2606.16748查阅完整论文,研究团队也在mypcbench.com上开放了测试环境、任务集和评估工具的完整代码。
---
Q&A
Q1:MYPCBENCH和现有的AI测试平台有什么本质区别?
A:现有的AI测试平台(如WebArena、OSWorld)通常在空壳环境里测试AI,应用里只有当前任务需要的最少量数据,不涉及用户的历史记录或个人信息。MYPCBENCH的核心区别在于,它在整个测试环境里预先填充了一个完整的虚构人物(Michael Scott)的真实数字生活,包括数年的银行交易、邮件往来、外卖记录、旅行历史等,并要求AI在理解这些个人数据的基础上完成任务,从而测试AI真正的"个人助手"能力。
Q2:MYPCBENCH里最难的任务类型是什么?
A:根据测试结果,"多步骤编排"和"汇总与报告"是最难的两类任务。前者要求AI跨越多个应用同时执行读取和写入操作;后者要求从大量历史记录中计算统计信息并输出到文档。在这两类任务上,除Claude系列外的所有模型完美率均低于16%。另外,需要同时操作7个以上应用的任务,除Claude系列和GPT-5.5外,其他模型完美率全部为零。
Q3:Claude模型在MYPCBENCH上表现最好,但它有什么主要的失败模式?
A:Claude系列有一个独特的"控制台脚本捷径"失败模式。Claude会绕过用户界面,直接用命令行工具调用网站后台接口来获取数据。当任务只需要查询信息时,这很高效;但当任务要求在用户界面上完成可见的操作(如拖动卡片、保存文件)时,Claude虽然通过命令行得到了正确答案,却没有在界面上执行必要的操作,导致需要"用户可见界面变化"的评分标准失败。