GPT-5.2 写 CUDA 算子,正确率 92%。同样的模型,给华为 Ascend NPU 写算子,正确率只有 4%。不是模型变笨了,是它压根没见过这类代码。公开数据几乎为零,专家寥寥无几,编译报错你还看不懂 —— 这就是 "新硬件冷启动" 的真实处境。
上海交大团队的 EvoKernel 不训新模型、不标新数据,而是让大模型像老工程师一样积累经验:每写一次算子,记住什么管用、什么不管用,下次优先调用最有价值的历史经验。结果:同一个 GPT-5.2,正确率从 4% 拉到 83%,最快的算子比 PyTorch 基线快了 42 倍。不仅如此,团队还将方法拓展到 DeepSeek 最新 mHC 架构的算子上,同样取得了显著效果。
该方案的早期实践已在昇腾 AI 创新大赛 2025 全国总决赛中斩获初创赛道金奖 ,项目获华为计算·梦想起航种子计划支持。相关团队成员亦在第十九届"挑战杯"全国揭榜挂帅擂台赛中获得擂主(特等奖第一名)。
算子(Kernel)是大模型直接运行在加速芯片上的底层计算程序 —— 矩阵乘法、卷积、Softmax 等每一个基础运算,都需要一段精细适配硬件的算子代码才能高效执行,它的调优和硬件适配,长期以来一直是需要专家参与的 “手艺活”。在 CUDA 生态里,算子开发有海量开源代码和成熟工具链做支撑,近期以来,大模型也能写出不错的 GPU 算子。但昇腾等国产 NPU 有自己的编程语言(如 Ascend C)和硬件架构,公开代码几乎为零、开发者社区尚在起步,大模型在这些新生态上近乎 "裸考"。
论文中的实验把这种落差量化得非常直接。以 GPT-5.2 为例,在 CUDA Level 1 任务上正确率可达 92%,迁移到 Ascend C 后只剩 14%;更难的 Level 2 任务,正确率从 90% 直接跌到 2%。公开数据少、专家经验稀缺、编译反馈不透明、性能调优高度依赖真实硬件 —— 这些因素共同构成了一堵典型的 "数据墙",现有模型并没有真正学会为新硬件编程,更多是在复用预训练中见过的 CUDA 模式。
 论文标题:Towards Cold-Start Drafting and Continual Refining: A Value-Driven Memory Approach with Application to NPU Kernel Synthesis
作者单位:上海交通大学、上海人工智能实验室 等
项目主页:https://evokernel.zhuo.li
arXiv 论文:https://arxiv.org/abs/2603.10846
论文标题:Towards Cold-Start Drafting and Continual Refining: A Value-Driven Memory Approach with Application to NPU Kernel Synthesis
作者单位:上海交通大学、上海人工智能实验室 等
项目主页:https://evokernel.zhuo.li
arXiv 论文:https://arxiv.org/abs/2603.10846 EvoKernel 想做的
不是再训一个模型
围绕这一冷启动难题,EvoKernel 给出的答案不是继续堆标注数据,也不是重新训练一个专门模型,而是设计了一套从初稿生成到持续优化的自演化智能体框架。系统分成两个连续阶段:
冷启动生成(Cold-Start Drafting):先找到一个能编译、能运行、结果正确的初始算子。 持续改善(Continual Refining):在有了第一个可行版本之后,再持续做延迟优化和性能改进。
图 1:EvoKernel 的整体框架。系统先在冷启动阶段生成可行初稿,再在共享记忆与验证反馈的帮助下持续做性能精炼。
这套框架最关键的设计,是论文提出的价值驱动记忆(Value-Driven Memory)。和常见的相似度检索不同,EvoKernel 不只是问 "哪些历史样本看起来更像当前任务",而是进一步学习 "哪些历史经验在当前阶段真正更有用"。为此,团队引入了阶段感知的 Q 值机制:在生成阶段,系统优先检索更可能帮助模型通过编译和正确性验证的经验;在精炼阶段,则优先保留更可能带来性能收益的优化轨迹、候选起点和上下文信息。
换句话说,EvoKernel 不是简单地 "给模型喂更多例子",而是在让模型逐渐学会:面对不同阶段的目标,应该参考哪类记忆,忽略哪类噪声。
为什么它不像传统智能体一样 "试一试运气"?
为了让这套记忆真正可用,团队还构建了多层验证机制。每一次生成的结果,都会经历 reward hacking 检查、编译验证、正确性校验和延迟测量四个环节:既要避免模型通过 Python 绑定层绕过算子实现,又要检查代码能否在真实 Ascend C 工具链中成功编译,并验证输出是否与 PyTorch 参考实现一致;只有通过这些检查,候选结果才会进入下一轮性能优化。具体而言,团队针对语义绕过、常量伪造、高层 API 替代等多类 reward hacking 模式,设计了规则筛查与智能体筛查两级反作弊机制,从源头降低无效结果进入记忆库的可能性。
也正因为验证器足够严格,EvoKernel 的迭代过程并不是提示词工程式的 "多试几次",而是围绕真实执行反馈不断调整检索策略、补充历史经验、扩大可用优化起点。
从方法上看,EvoKernel 的关键并不只是 "有记忆",而是它能够逐步学会哪些记忆在当前阶段最值得取用。这也是它和一般基于静态相似度检索的方法最主要的区别。
主结果:从 4% 正确率一路拉到 83%
团队基于 KernelBench 构建了 NPU 版本评测环境,经过 30 轮的迭代后,EvoKernel 在 GPT-5.2 上把整体结果显著拉升:
整体编译率从 11.0% 提升到 98.5% 整体正确率从 4.0% 提升到 83.0% 在更难的 Level 2 任务上,实现了 100% 编译率和 76% 正确率
图 2:论文中的主实验结果。表中同时给出了 Level 1、Level 2 和 Overall 三组结果,也展示了首轮到最终轮的变化幅度。对 GPT-5.2 而言,EvoKernel 在整体编译率和正确率上都显著优于 Pass@k、Refinement 和 Codex。
作为对比,在相同 30 次预算下,Codex 智能体的整体结果为 83.0% 编译率和 46.0% 正确率,传统精炼基线则只有 71.5% 编译率和 22.0% 正确率。也就是说,即便 Codex 拥有更强的自主工具调用能力,EvoKernel 依然在这个数据稀缺的 NPU 算子开发场景里,表现出了更强的稳定性和成功率。
做对还不够
EvoKernel 还在继续把它做快
论文里另一个很值得关注的点,是 EvoKernel 不只停留在 "生成一个能跑的算子",而是在正确版本出现之后,继续做持续优化。
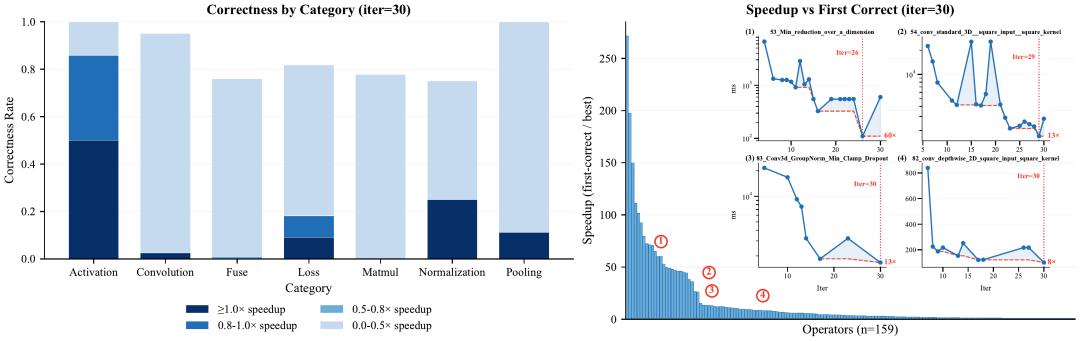
图 3:EvoKernel 的优化结果。左侧展示不同类别算子在正确率和加速比上的分布,右侧展示同一算子从首个正确版本到最佳版本的持续优化收益。
实验显示,在已经找到首个正确版本的前提下,系统进一步通过持续精炼,把算子的中位数速度提升做到 3.60 倍,四分位区间为 1.38 倍到 10.05 倍。更重要的是,这并不是少数偶然样本带来的假象。论文统计了 159 个至少出现过 "正确且可继续优化" 候选的算子,发现其中不少都能随着迭代持续获得稳定收益,部分算子相对首个正确版本的加速甚至超过 200 倍。
这意味着 EvoKernel 并不只是一个代码修复工具,而是开始展现出更接近算子工程师的优化能力。
记忆为什么有用
因为它真的能跨任务迁移
如果说主结果回答的是 "EvoKernel 能不能把一个任务做出来",那么这部分结果回答的则是 "它能不能把经验留下来,下次继续用"。
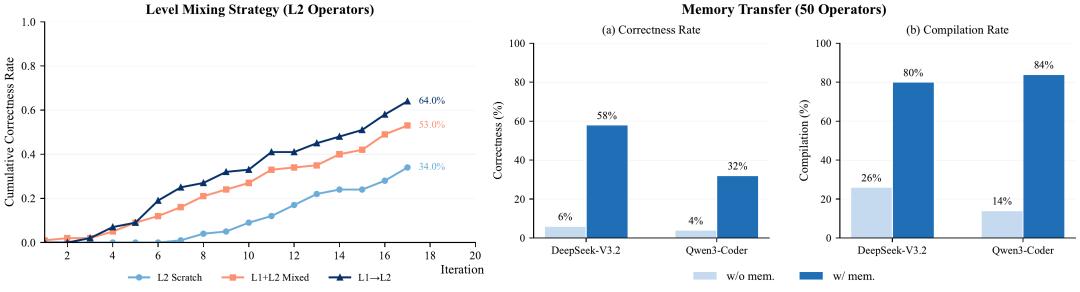
图 4:EvoKernel 在跨难度、跨模型设置下的迁移能力。
团队发现,当系统先在更简单的 L1 任务上积累经验,再迁移到更难的 L2 任务时,正确率上升明显快于从零开始。在第 17 次迭代时,L1 → L2 的迁移设置已经达到 64% 的 L2 正确率,显著超过混合训练和从零开始两种方式。
更进一步,论文还验证了跨模型迁移。用 GPT-5.2 构建出的记忆库,能够把 DeepSeek-V3.2 在保留测试集上的编译率从 26% 提升到 80%,正确率从 6% 提升到 58%;对 Qwen3-Coder-30B,同样可以把编译率从 14% 提升到 84%,正确率从 4% 提升到 32%。这些结果说明,这种记忆更像是一种可复用的 "任务经验资产",而不只是一次性上下文拼接。
不止 KernelBench
它还开始走向更真实的工程场景
如果一套方法只在基准测试上好看,意义其实有限 —— 已有研究表明,在 KernelBench 上表现优异的模型,面对新出现的算子或真实硬件需求时,正确率可能直线下降。EvoKernel 的另一个亮点,是团队把它继续扩展到了主实验分布之外的任务。
团队额外构建了一组包含 70 个 Attention 类算子的测试集(Attention Set)。这些算子从 FlashAttention、xformers 等主流开源社区仓库中手动筛选而来,覆盖了当前大模型推理与训练中需求最迫切、迭代最快的 Attention 算子变体 —— 这恰恰是芯片厂商在实际落地中优先需要解决的算子类别。
在这组更贴近真实工程需求的任务上,EvoKernel 在 CUDA 平台上达到了 100% 编译率和 97.1% 正确率;在昇腾平台上,也取得了 100% 编译率和 78.6% 正确率。更进一步,在面向 DeepSeek 今年 1 月份发布的流形约束超连接(Manifold-Constrained Hyper-Connections, mHC)新架构的 15 个相关算子上,EvoKernel 成功得到 10 个正确实现,其中 6 个超过 PyTorch 基线,代表性结果包括 SinkhornKnopp 的 41.96 倍加速。

图 5:在 DeepSeek mHC 算子上的扩展结果。EvoKernel 不只在原始 KernelBench 分布上有效,也开始展现出对新算子族和新架构模式的适配能力。
换句话说,这项工作展示出的并不只是对某个基准测试的适配能力,而是在向更真实的跨任务、跨场景泛化迈出一步。
这项工作的意义
可能不止于 NPU 算子开发
从更大的视角看,EvoKernel 的意义可能不止于 NPU 算子开发。本质上,它回答的是这样一个问题:当目标领域几乎没有现成训练数据、只有严格可验证反馈时,通用大模型还有没有办法通过非参数化、可积累的方式逐渐掌握新技能?
这篇工作给出了一个积极信号。随着硬件生态越来越分化,真正稀缺的也许不只是算力,而是能够快速适应新架构、新领域专用语言(DSL)、新工具链的工程能力。EvoKernel 试图把这部分能力,从 "依赖少数专家" 变成 "可以被记忆、检索和持续放大的系统能力"。
一句话总结
EvoKernel 提出了一种面向数据稀缺 NPU 编程场景的价值驱动记忆框架,不依赖昂贵微调,仅通过可验证反馈和跨任务经验积累,就把 GPT-5.2 在 Ascend C 算子开发任务上的整体正确率从 4.0% 提升到 83.0%,并在正确初稿基础上实现了 3.60 倍的中位数性能优化。
如果你对 NPU 算子开发、跨硬件代码生成或 LLM agent 在系统软件领域的应用感兴趣,欢迎访问项目主页(https://evokernel.zhuo.li)获取更多细节。本工作由上海交通大学人工智能学院郑雨杰、李卓主导完成,王翰竟(上海人工智能实验室)参与合作,温睦宁(助理研究员,通讯作者)和温颖(副教授)担任指导,也欢迎通过论文联系方式与团队交流合作。