作者 林易
编辑 重点君
2025年尾声,全球科技风向标再次转动。
年初,硅谷和华尔街都在屏息以待OpenAI GPT-5降临,笃定它会像前几代模型一样惊艳。然而,行至年末,这种期待很大程度上落空了。
12月29日,美国著名科技媒体《连线》发布了一篇具有象征意义的年终头条——《再见,GPT-5。你好,千问》。
文章没有否认GPT的地位,但敏锐地捕捉到了潮水的转向:GPT-5未能如预期激起市场热情,而来自中国的开源模型阿里千问(Qwen),性能优异,适于灵活部署应用,2026年将属于千问。
《连线》杂志观察指出,尽管美国OpenAI的GPT-5、谷歌的Gemini 3以及Anthropic的Claude通常得分更高,但千问、DeepSeek等中国模型性能也稳居第一梯队,并且变得越来越受欢迎,原因在于它们既性能优异,又易于开发者灵活调整和使用。
《连线》资深编辑Will Knight在文中提出了一个新的评估维度:“衡量任何AI模型价值的关键标准,不应仅限于其聪明程度,更应看它被用于构建其他应用的广度。”
如果以此为尺,过去一年无疑是全球大模型版图重构的一年。全球AI格局正在从一超多强的单极世界,演变为中美双核的多极世界。中国大模型正在从追随者变成并跑者。
开源:一场权力的交接时间回到两年前,Meta Llama系列曾是全球开源模型的绝对王者。彼时的中国AI圈,叙事主线往往是“做中国版Llama”,许多创业公司甚至拿着套壳Llama的模型去融资。
进入2025年,Meta基础模型性能明显掉队,Llama 4 没达到LM Arena 基准测试的第一梯队水平,创始人扎克伯克开始从OpenAI等竞对那里天价挖人、频上头条;同时,OpenAI的gpt-oss等开源模型性能较弱,没能吸引太多开发者使用。
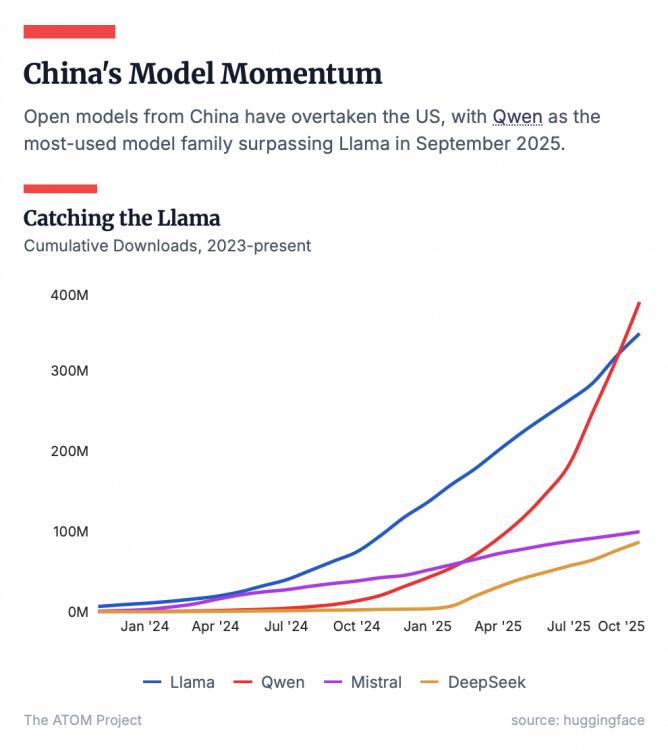
到了2025年下半年,开源的权杖发生了转移。根据全球最大的AI开源社区HuggingFace的数据,2025年7月是一个分水岭:中国开源模型的下载量首次超过了美国,其中千问位居第一。
截至2025年10月,千问全球下载量已突破7亿次,超越Llama成为全球第一大开源模型。更具标志性的是,在OpenRouter这个更能反映开发者偏好的第三方API聚合平台上,千问的调用量一度冲至全球第四,仅次于几个头部闭源巨头,且经常在编程等细分领域霸榜。
《连线》在调查中发现:甚至连曾经的开源先驱Meta,据传也在内部使用千问来协助开发其新一代模型。这在两年前简直无法想象。
而在美国倡导开源模型发展的非营利组织Laude Institute,其联合创始人Andy Konwinski更是直言:“许多科研人员都在使用Qwen,因为它是目前最好的开源大模型。”
究其原因,是阿里从一开始就选择了一条比Meta等更彻底的开源路线。
一方面,相较于几乎不开源的OpenAI,阿里在模型构建与持续更新方面投入了更多精力,且千问技术细节更公开透明,阿里经常发表论文,详述新的工程和训练技巧,与美国大型科技公司的封闭形成鲜明对比。
另一方面,不同于一些公司“开源小模型、闭源大模型”的试探性策略,阿里的打法更类似安卓系统:一口气开源了近400款模型。不仅涵盖了0.5B到110B的全尺寸参数,覆盖了文本、图片、语音、视觉等全模态,还支持119种语言。
这种策略逐渐构建了生态护城河。当一个开发者想要开发一款智能硬件时,需要一个小参数模型;当进行复杂推理时,需要一个大参数模型。过去,开发者可能需要拼凑不同厂商的模型,而现在,千问就能提供了一整套标准化的解决方案。
HuggingFace在2025年9月底公布的开源模型榜单中,前十名有7款来自通义。斯坦福HAI研究所发布的报告也显示,2024年重要大模型中,阿里入选6个,AI贡献度位列全球第三。
显然,中国科技公司不再只是全球AI的应用层玩家,它们开始掌握模型层的技术标准和话语权。
落地:模型的隐形战场模型只有落地到千行百业的具体应用和业务场景中,才能产生实际价值。
相比开源社区可见的下载量,AI落地产业往往不为人知。对于大多数企业而言,模型只是技术底座,他们不需要对外传播自己使用了什么模型,只需要产品好用。
《连线》在文章中描述了这样一个场景:在杭州的智能眼镜初创公司Rokid,记者和工程师正在用智能眼镜实时翻译对话,并将文字投射在眼前。背后驱动这一切的,正是千问的开源模型。
而这只是冰山一角。
基于千问,AI社区已经形成了围绕它的庞大生态。千问模型发布后,vLLM、SGLang、苹果MLX等最主流的AI框架会第一时间上线支持;英伟达、联发科等硬件厂商会实现Day 0的适配;Ollama、Kaggle、LMSYS org、openRouter、HuggingFace等开发者最常用的应用、工具、平台、社区也会同步上线新的开源模型。
这意味着,任何一家企业想要使用千问,由于工具链的完备,其边际成本被降到了最低,大大加速AI落地和创新速度。
从北京到硅谷,从华强北到义乌小商品市场,千问横扫大公司、中小企业和创业公司市场,成为实际上落地最多的大模型。
在美国,硅谷明星公司Airbnb、Perplexity和英伟达均已将千问纳入技术栈。在中国,比亚迪等新能源车企将千问集成到新款车载仪表盘助手中;OPPO、vivo等手机厂商则在端侧大量部署千问的小参数模型。
国际权威调研机构沙利文(FrostSullivan)的报告显示,在2025年上半年的中国企业级大模型调用市场中,千问占比位列第一,服务了超过100万家客户。
这种广度正是《连线》所强调的新标准:当一个模型被用于构建成千上万个互不相同的应用时,它就具有了比单纯刷榜更高的生命力。
正如Laude Institute创始人Andy Konwinski对《连线》所说,“狭窄的基准测试衡量的往往是数学或编程等技能,却以牺牲确保模型产生重大影响为代价。当基准测试不能代表真实使用或世界上待解决的问题时,最终会陷入方向错误的模式。”
编程:被低估的垂类赛道值得关注的是,在所有产业落地场景中,AI Coding(人工智能编程)正在成为最具赚钱效应的AI赛道。
以Anthropic为例,2025年,凭借旗下Claude模型在编程领域的表现,营收实现了爆发式增长。其年化营收运行率预计在年底接近70亿-90亿美元,仅仅一年翻了近7-9倍。在完成F轮融资后,其估值已飙升至1830亿美元,二级市场甚至给出了2200亿美元的隐含估值。
Anthropic的成功在于,其API收入中很大一部分来自Cursor和GitHub Copilot等编程工具的调用。单这一项,就贡献了数十亿的营收。
毫无疑问,AI Coding正在彻底改变程序员和企业的工作流,程序员不再埋头写程序,而是聚焦更高维度的架构和创新,通过大模型快速生成代码,然后修改迭代,这种新工作范式极大提升了验证想法的速度。
OpenAI联合创始人、提出Vibe Coding(氛围编程)概念的Andrej Karpathy甚至感叹:“作为一名程序员,我从未感到如此落后……”
在中国,阿里拥有从AI Coding模型到平台的最全面布局,且正在快速赢得市场。
在模型层,7月23日阿里开源了千问AI编程大模型Qwen3-Coder。这款模型以480B参数激活35B参数的MoE架构,原生支持256K上下文,编程能力登顶全球开源阵营,不仅超越了GPT-4.1,更比肩全球最强的编程模型Claude 4。OpenRouter数据显示,Qwen3-Coder上线后调用量一周暴增1474%,位列编程领域全球第二。
在应用层,通义灵码已经成为国内渗透率最高的辅助编程工具。
比如,在金融领域,中国建设银行、工商银行、平安集团等巨头已全面铺开;平安集团超1.5万名研发工程师使用AI编码,部分新项目代码AI生成占比超70%;在汽车领域,吉利、蔚来、小鹏汽车的研发团队中,代码AI生成占比普遍达到30%以上;在SaaS领域,用友网络超50%的研发人员使用通义灵码,AI代码生成占比达到37%。
截至2025年9月,通义灵码累计为开发者生成超60亿行代码。助力300万开发者减少重复性编码、测试及缺陷修复工作,聚焦架构设计与技术创新。
为了进一步抢占高地,阿里还发布了Agentic编程平台Qoder,集成全球顶尖模型,一次可检索10万个代码文件,将数天的网页开发工作缩短至十分钟。
通过深度集成全球顶尖编码模型的Qoder和深度集成Owen-coder 系列模型的通义灵码,阿里云形成了“全球创新→本土深耕→生态落地"的全面布局。而这方面的价值,目前还被市场远远低估了。
对于企业而言,AI Coding能力是通往通用人工智能的必经之路。阿里巴巴集团董事兼首席执行官,阿里云董事长兼首席执行官吴泳铭,曾在云栖大会上曾系统阐述过通往ASI(超级人工智能)的三个阶段,其中第二阶段“自主行动”的核心,就是大模型具备Coding能力。因为只有掌握了代码,AI才能像工程师一样拆解任务、操作工具,最终进化为能够自我迭代的Agent。
全栈:顶级AI巨头的入场券当模型能力日益趋同,竞争焦点开始转向更综合的全栈能力。
过去三年,全球科技圈的主流叙事中有且仅有两个主角:英伟达负责卖铲子,提供GPU硬件基础;OpenAI负责挖金矿,凭借Scaling Law定义前沿模型。
但2025年,这种分工正在被谷歌的强势回归打破。过去一年,凭借Gemini 2.5/3.0系列模型和TPU v6/v7芯片的算力支撑,谷歌不仅在模型能力上抹平了与OpenAI的代差,更利用“芯片+云+模型”的垂直整合全栈技术闭环,大幅拉低了推理成本。有分析指出,谷歌提供同等推理服务时的底层成本,可能仅为对手的两成。
随着AI应用爆发,推理算力需求指数级增长,对于企业来说,成本就是生命。
因此,不难理解谷歌云亮眼的财报表现:2025年第三季度,新增客户数量同比增长近34%,超过70%的客户正在使用它的AI产品;前三季度,总营收达410亿美元,同比增长31.2%,显著高于亚马逊AWS和微软Azure,在北美三大云厂商中增长最快。这种增长很大程度上得益于其全栈AI能力的释放。
在全球科技巨头中,阿里的发展路径与谷歌最为相似,从模型到B端市场再到C端应用,“西谷东阿”正日益成为硅谷和华尔街的共识。过去一年,两家科技巨头的股价也都大幅上涨超过60%。
和谷歌类似,阿里通过阿里云打造了面向全球的AI基础设施,从底层芯片、超节点服务器、高性能网络、分布式存储,到人工智能平台、模型训练推理服务,形成了全栈AI云技术能力。

全栈布局带来的优势显而易见。未来,企业需要的不仅仅是一个API接口,而是结合了私有数据、算力调度和安全合规的一整套解决方案。有的企业需要API调用,有的需要自己训模型,有的需要RAG(检索增强生成)。这些复杂的需求,只有覆盖IaaS、PaaS、MaaS的全栈厂商才能完美承接。
这种“云+模型”的一体化战略,正在成为阿里在B端市场的杀手锏。
作为全栈人工智能服务商,阿里正在推进三年3800亿人民币的AI基础设施建设计划,并持续追加投入。阿里云也正在为中国乃至全球提供智能算力网络。
结语《连线》的标题——“再见,GPT-5。你好,千问”,并不意味着行业终局。OpenAI和谷歌依然拥有最顶尖的模型,英伟达的算力霸权短期依然难以撼动。但2025年,AI不再是单极世界。
当全球的开发者开始习惯调用千问的开源模型,当硅谷的创业公司开始将业务跑在来自杭州的模型上,中国AI在全球科技版图中就拥有了不可替代的生态位。
2026年,或许正如《连线》所言,将是“千问之年”。但这不仅属于千问和阿里,更属于所有相信开放、拥抱开源的人。