近日,美团推出全新多模态统一大模型方案STAR(STackedAutoRegressiveSchemeforUnifiedMultimodalLearning),凭借创新的"堆叠自回归架构+任务递进训练"双核心设计,实现了"理解能力不打折、生成能力达顶尖"的双重突破。
在GenEval(文本-图像对齐)、DPG-Bench(复杂场景生成)、ImgEdit(图像编辑)等benchmark中,STAR实现了SOTA性能;用最简训练逻辑与紧凑模型设计让统一多模态大模型真正走向工业级落地。

论文标题:STAR:StackedAutoRegressiveSchemeforUnifiedMultimodalLearning
项目主页:https://star-mm-ai.github.io
代码地址:https://github.com/MM-MVR/STAR

一、行业痛点:统一多模态大模型的“能力诅咒”
在通向AGI的进程中,将“视觉理解”与“图像生成”统一于单一参数空间被视为多模态大模型的圣杯,然而实践层面却长期受制于“能力诅咒”,具体表现为三重矛盾。
1.优化目标互斥——语义对齐与像素保真的零和博弈
理解任务的核心是"语义对齐与逻辑推理"——比如识别图像中的物体、回答图文相关问题,需要模型精准捕捉跨模态的语义关联;而生成任务的核心是"像素保真与创意表达"——比如根据文本描述生成高清图像,需要模型兼顾细节还原与内容连贯性。两者的优化目标、特征空间显著不同,导致联合训练陷入零和博弈:强化生成能力,理解准确率会下降;深耕理解任务,生成图像的清晰度、语义一致性会打折。
2.训练范式繁复——从零训练与混合架构的双重瓶颈
现有两条技术路线均面临高昂训练成本:
(1)端到端从零训练需在亿级图文-生成配对数据上做多任务平衡,优化空间维度高达千维,超参敏感性呈指数级放大,训练周期常以“月”为单位;
(2)混合架构通过扩散模型与自回归模型的组合实现功能覆盖,但需要设计复杂的特征转换桥(featurebridge)、额外的适配器(adapter)或复合损失(hybridloss),增加了整体调参难度。
3.能力扩展退化——灾难性遗忘与容量饱和
在预训练理解骨干上增量引入生成任务时,模型出现典型的灾难性遗忘(catastrophicforgetting),原本擅长的图像问答、逻辑推理能力会显著下降。其根源在于参数容量饱和与表征干扰——生成任务的像素级扰动在特征空间形成噪声,改变了早期对齐的语义特征,致使“全能扩展”成为“轮换专精”。
面对这些行业痛点,美团MM团队提出了一个直击核心的问题:能否在完全保留多模态理解能力的前提下,持续、高效地增强模型的生成与编辑能力?STAR方案的诞生,给出了肯定且可扩展的解答。
二、核心创新:重构多模态学习的"能力成长法则"
STAR的关键不是单一技术突破,而是构建了一套“能力叠加不冲突”的多模态学习体系,核心围绕「冻结基础+堆叠扩展+分阶训练」范式,通过三大核心设计实现「理解、生成、编辑」三大能力的统一,同时避免互相干扰。整个框架由“堆叠同构AR模型+任务递进训练+辅助增强机制”三大部分协同组成。
1、核心架构:堆叠同构AR模型(Stacked-IsomorphicAR)
STAR的核心架构创新,是其"堆叠同构AR模块"的设计,彻底简化了多模态能力扩展的复杂度,就像给模型"搭积木"一样灵活高效:
(1)同构设计,零适配成本:新增的堆叠模块与基础AR模型采用完全相同的架构(自注意力机制+前馈神经网络),参数初始化直接复用基础模型的顶层参数。这意味着新增模块无需重新学习基础特征,能快速适配现有模型的特征空间,避免了传统混合架构中"特征转换桥"的复杂设计;
(2)单目标训练,极简优化:无需设计额外的损失函数,仅通过标准的"下一个token预测"目标即可完成生成与编辑能力的训练。这一目标与基础模型的训练目标完全一致,确保了训练过程的稳定性,大幅降低调参难度;
(3)参数紧凑,落地友好:STAR-3B仅在Qwen2.5-VL-3B基础上新增1.2B参数(16层堆叠模块),STAR-7B新增3B参数(14层堆叠模块),却实现了生成能力的跨越式提升。STAR的紧凑设计非常适合工业化部署,能有效降低推理成本。
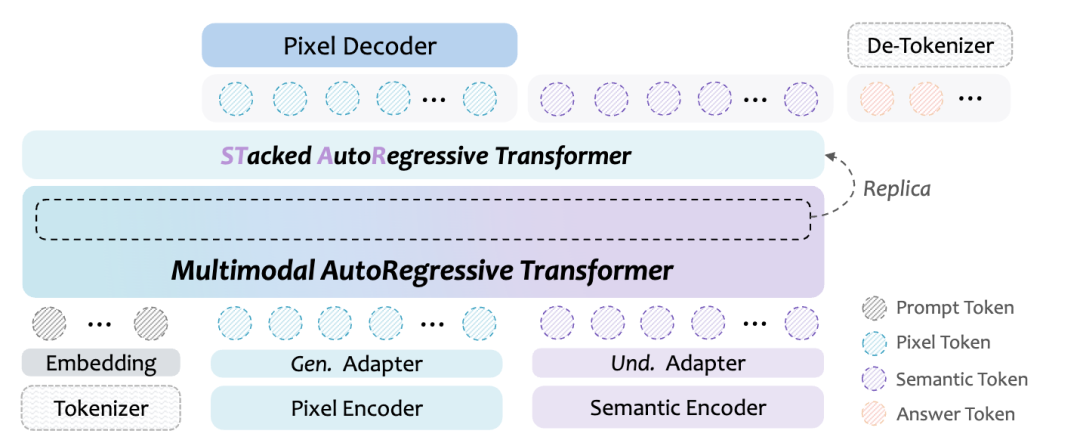
2、核心范式:任务递进式训练(Task-ProgressiveTraining)
STAR打破了传统统一模型“混在一起训练”的模式,把多模态学习拆成四阶段递进流程,每一步都冻结已有核心能力,扩展新技能:
(1)第一阶段(VQ训练):先训练“图像分词”能力,训练STAR-VQ把图片拆成细粒度离散token,为后续生成/编辑打下基础;
(2)第二阶段(文本生图预训练):在冻结的理解模型上,堆叠AR模块专门学文生图任务,只更新新模块参数,不碰原有理解能力;
(3)第三阶段(AR-扩散对齐训练):单独优化扩散解码器,让生成的图片更清晰,其他模块保持冻结;
(4)第四阶段(统一指令微调):联合训练堆叠AR和扩散解码器,同时掌握“生图+编辑”,用梯度停止机制避免新任务干扰旧能力。
STAR通过任务递进式训练,让每一步新能力的学习都不破坏已有成能力,实现“理解能力不退化,生成/编辑能力逐步增强”。
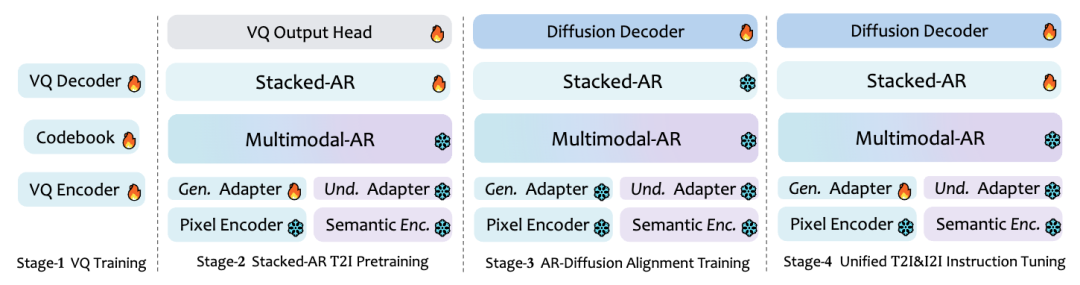
3、辅助增强机制:两大关键优化
1.高容量图像量化器(STAR-VQ)
传统VQ模型拆分图片粗、细节丢失多,STAR-VQ做了两大升级:
(1)规模扩容:代码本规模从16384提升到65536,向量维度从8维提升到512维,能捕捉更多图像细节;
(2)避免崩溃:通过新增codebook映射层,解决大codebook训练中常见的码本崩溃问题,保证所有token都能被有效利用;
(3)核心作用:生成更精准的视觉token,让后续生成/编辑任务能还原更细腻的图像细节。
2.隐式推理机制(ImplicitReasoning)
面对复杂提示,传统生成模型容易出现语义错位、细节遗漏的问题。STAR的隐式推理机制,让模型学会"先推理,再生成":
(1)当接收到复杂提示时,冻结的基础AR模型先进行推理,生成蕴含核心知识的隐式latenttokens;
(2)这些latenttokens作为条件输入,引导堆叠模块进行图像生成。这一设计实现了"语义推理"与"像素生成"的解耦,让生成过程更有逻辑,大幅提升了复杂场景下的语义对齐度。
三、实验结果
STAR的突破性表现,得到了权威benchmark的全面验证,在理解、生成、编辑三大任务中均展现出顶尖实力。
1.生成任务:
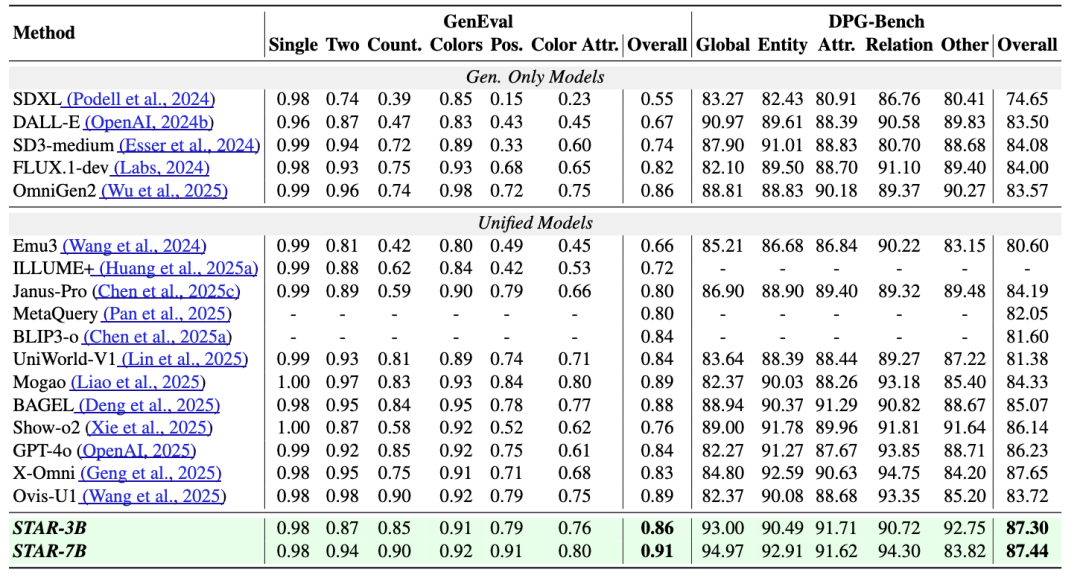
在文本-图像生成的核心benchmark中,STAR的表现惊艳:
(1)GenEval(语义对齐权威benchmark):STAR-7B以0.91的综合得分刷新SOTA。在物体计数、颜色属性、空间关系、实体属性等6个子任务中,STAR有5项排名第一;
(2)DPG-Bench(复杂场景生成benchmark):STAR-7B以87.44的得分领先,在多物体组合、复杂场景描述等任务中表现突出,生成的图像不仅细节丰富,还能精准还原文本中的逻辑关系;
(3)WISEBench(世界知识推理benchmark):STAR-7B以0.66的综合得分,超越同类统一模型,证明其隐式推理机制能有效利用世界知识,提升复杂提示的生成质量。
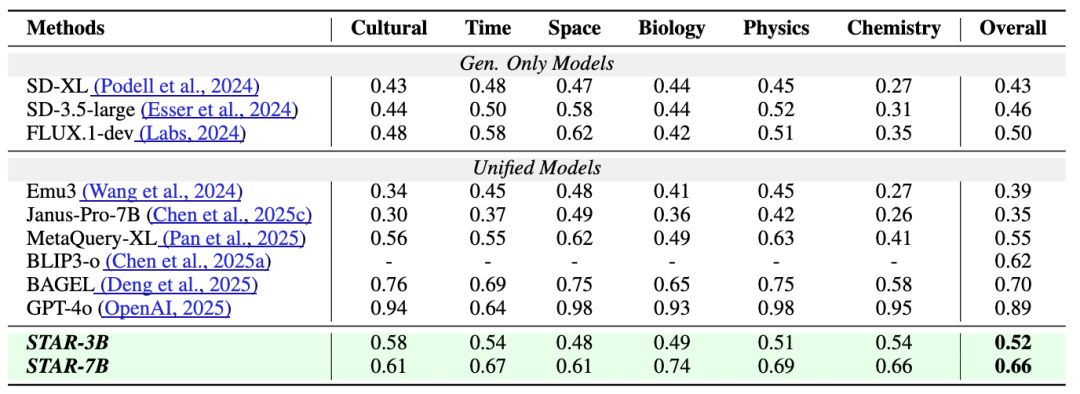
2.编辑任务:
(1)ImgEdit(覆盖9类编辑任务):STAR-7B以4.34的综合得分刷新SOTA。在"物体提取""动作编辑"等子任务中,得分分别达到4.19、4.60,领先同类模型;
(2)MagicBrush(语义编辑benchmark):STAR-7B的CLIP-I得分达0.934(语义一致性),L1误差低至0.056(像素保真度)。这意味着STAR在完成编辑任务的同时,能最大程度保留原图的核心内容,避免"过度编辑"或"语义偏离"。

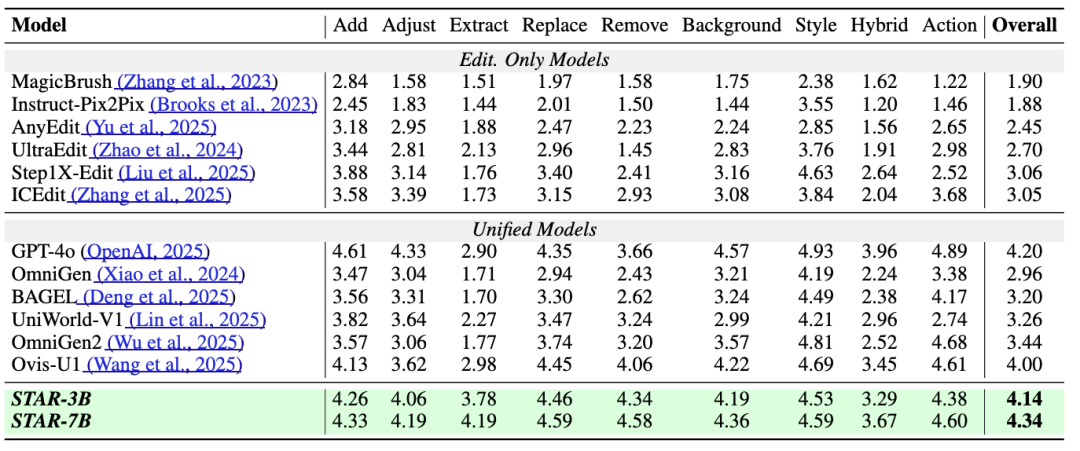
3.理解任务:
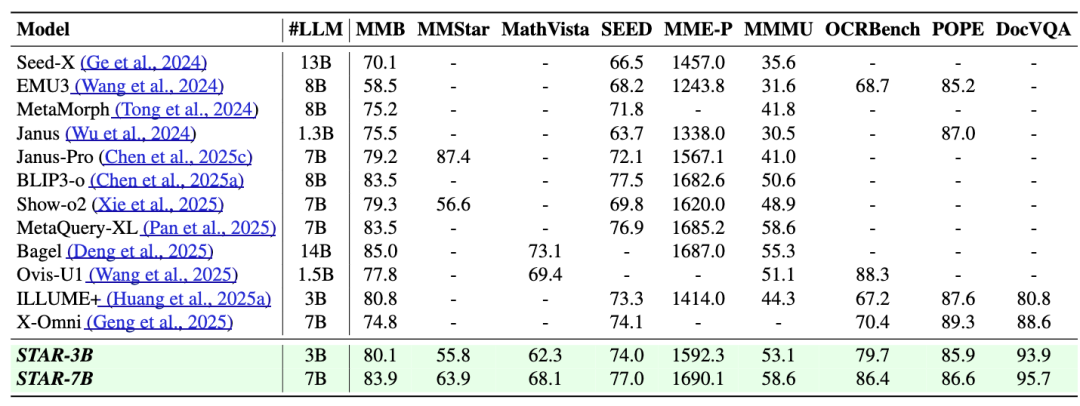
即便专注于增强生成与编辑能力,STAR的理解能力依然保持顶尖水平。在9大权威理解benchmark中,STAR的表现领先于同类多模态模型。
四、总结与展望
STAR的本质是“用最简洁的结构实现最全面的能力统一”:通过“任务递进”解决训练冲突,通过“堆叠同构AR”降低扩展成本,通过“STAR-VQ+隐式推理”提升能力上限,最终实现“理解、生成、编辑”三大任务的顶尖性能,为多模态模型的可持续扩展提供了全新思路。
STAR为多模态模型的无干扰、可扩展扩展提供了全新技术路径,后续可从以下方向进一步探索:
(1)能力边界扩展:在现有理解、生成、编辑基础上,纳入视频生成、3D重建等更复杂的多模态任务,验证框架的泛化性;
(2)效率优化:当前模型仍需多阶段训练,未来可探索更高效的联合训练策略,或轻量化堆叠模块以降低部署成本;
(3)推理能力深化:进一步强化隐式推理机制,结合外部知识库或强化学习,提升模型在超复杂逻辑、跨领域知识场景下的生成准确性;
(4)多模态融合升级:拓展文本、图像之外的模态(如语音、触觉),构建更全面的通用多模态系统,推动人工通用智能(AGI)的发展。