机器人操作模型虽然在语义理解上取得巨大成功,但往往被困在 2D 图像的「错觉」中。现有的机器人操作模型主要依赖 2D 图像作为输入,这意味着它们容易丢失关键的深度信息和 3D 几何结构。
具体而言,基于点云的方法受限于稀疏采样,导致细粒度语义信息的丢失;基于图像的方法通常将 RGB 和深度信息输入到在 3D 辅助任务上训练的 2D 骨干网络中,但它们纠缠在一起的语义和几何特征对现实世界中固有的深度噪声非常敏感,从而干扰了语义理解。

图 1:不同方法的对比
针对这一痛点,Dexmal 原力灵机作者团队提出 SpatialActor,该工作核心在于 「解耦」(Disentanglement):它不再将视觉信息混为一谈,而是明确地将语义信息(这是什么?)与空间几何信息(它在哪里?形状如何?)分离开来,从而实现语义流与空间流的双流解耦与后期融合。
作者通过引入显式的 3D 空间编码器,并将其与强大的视觉语言模型结合,使机器人不仅能「读懂」指令,更能「感知」三维空间。作者在包含 50 多个任务的多个仿真和真实世界场景中评估了 SpatialActor。它在 RLBench 上取得了 87.4% 的成绩,达到 SOTA 水平;在不同噪声条件下,性能提升了 13.9% 至 19.4%,展现出强大的鲁棒性。目前该论文已被收录为 AAAI 2026 Oral,并将于近期开源。
 论文名称:SpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation
论文链接:https://arxiv.org/abs/2511.09555
项目主页:https://shihao1895.github.io/SpatialActor/
论文名称:SpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation
论文链接:https://arxiv.org/abs/2511.09555
项目主页:https://shihao1895.github.io/SpatialActor/ 方法与架构
作者认为,机器人操作本质上需要两种能力的协同:一是对任务目标的语义理解(由 VLM 提供),二是对环境几何的精确把控(由 3D 表征提供)。SpatialActor 并没有试图训练一个全能的端到端网络,而是采用了一种「双流解耦 - 融合」的架构设计。
整体架构

图 2:SpatialActor 架构概览
该架构采用了独立的视觉与深度编码器。语义引导几何模块(SGM)通过门控融合机制,将来自预训练深度专家的鲁棒但缺乏细粒度信息的几何先验与含噪但有逐像素细节的深度特征自适应地结合,从而生成高层几何表征。
在空间 Transformer(SPT)中,低层空间线索被编码为位置嵌入,用以驱动空间交互。最后,视图级交互优化了视图内的特征,而场景级交互则整合了跨视图的跨模态信息,为后续的动作头提供支持。
语义引导几何模块(SGM)
由于传感器的局限性和环境干扰,现实世界的深度测量往往含有噪声,而 RGB 图像则能提供高信噪比的语义线索。大规模预训练深度估计模型学习到了平滑的 “语义到几何” 映射,能够提供鲁棒且通用的几何先验。相比之下,原始深度特征虽然保留了细粒度的像素级细节,但对噪声高度敏感。
为此,SGM 模块通过一个冻结的大规模预训练深度估计专家模型从 RGB 输入中提取鲁棒但粗粒度的几何先验,同时利用深度编码器从原始深度中提取细粒度但含噪的几何特征。如图 3 (a) 所示,SGM 模块通过一个多尺度门控机制自适应地融合这些特征,从而生成优化后的几何表征;该表征在保留细微细节的同时降低了噪声,并与语义线索保持对齐。

图 3:语义引导几何模块和空间 Transformer
空间 Transformer(SPT)
如图 3 (b) 所示,SPT 模块旨在建立精确的 2D 至 3D 映射并融合多模态特征,是生成精准动作的关键。首先,模块将视觉得到的空间特征与机器人本体感知信息(如关节状态)融合。利用相机内外参矩阵和深度信息,模型将图像像素坐标转换为机器人基座坐标系下的三维坐标,并采用旋转位置编码技术将这些三维几何信息嵌入特征中,赋予其低层的空间感知。
在特征交互层面,SPT 依次执行视图级和场景级注意力机制:前者优化单视图内部表征,后者聚合所有视图与语言指令特征,实现跨模态的全局上下文融合。最终,解码器通过预测热力图确定动作的三维平移位置,并基于该位置的局部特征回归计算旋转角度和夹爪开闭状态,完成端到端的动作生成。
实验结果
为了全面评估 SpatialActor 的有效性,作者在仿真和真实世界环境中均开展了实验,既比较其与当前最先进方法的表现,也考察其在噪声干扰下的鲁棒性,并进一步验证其在真实机器人上的实际表现。
仿真基准测试结果

表 1:RLBench 仿真测试结果
作者给出了 SpatialActor 在 18 个 RLBench 任务及其 249 种变体上的成功率。SpatialActor 取得了最佳的整体性能,超越了此前的 SOTA 模型 RVT-2 6.0%。值得注意的是,在诸如 Insert Peg(插销钉)和 Sort Shape(形状分类)等需要高空间精度的任务中,SpatialActor 的表现分别优于 RVT-2 53.3% 和 38.3%。
不同程度噪声下的表现

表 2:不同程度噪声下的表现
在噪声实验中,作者通过加入不同强度的高斯扰动模拟噪声。结果表明,无论是轻度、中度还是重度噪声,SpatialActor 的表现都始终明显优于 RVT-2,平均成功率分别提升 13.9%、16.9% 和 19.4%。在诸如 Insert Peg(插销钉)这类需要高精度对位的任务中,这一差距更为突出,在三档噪声下分别高出 88.0%、78.6% 和 61.3%,展现出对噪声干扰的强鲁棒性。
真机实验结果

图 4:真机任务
在真机实验中,作者使用一台配备 Intel RealSense D435i RGB-D 相机的 WidowX 单臂机器人;并采用 8 个不同的任务,共计 15 种变体。
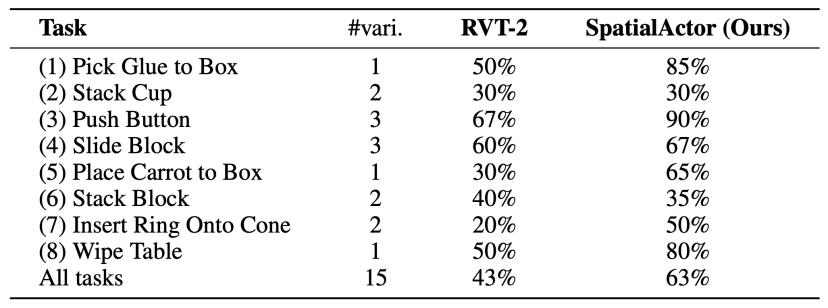
表 6:真机结果
真机实验结果如表 6 所示,SpatialActor 的表现持续优于 RVT-2,各任务平均提升约 20%,证明其在真实场景中的有效性。为了评估针对分布变化的鲁棒性,作者在被操作物体、接收物体、光照和背景发生变化的情况下对 SpatialActor 进行了测试。在这些多样且极具挑战性的条件下,SpatialActor 始终保持了高水平表现,有力证明了其在复杂真实世界场景中的强大鲁棒性与泛化能力。
结论
在本文中,作者提出了 SpatialActor,这是一个用于机器人操作的鲁棒空间表征框架,旨在解决精确空间理解、传感器噪声以及有效交互带来的挑战。SpatialActor 将语义信息与几何信息进行了解耦,并将几何分支划分为高层和低层两个组件:SGM 将语义引导的几何先验与原始深度特征自适应融合,以构建鲁棒的高层几何;而 SPT 则通过位置感知交互捕捉低层空间线索。
在 50 多个仿真和真实世界任务上进行的广泛实验表明,SpatialActor 在多样化的条件下均取得了更高的成功率和强大的鲁棒性。这些结果凸显了解耦的空间表征对于开发更加鲁棒且具备泛化能力的机器人系统的重要性。
附论
机器人操作可以分解为两个维度:空间感知与时序理解。前者关注如何将视觉与语言映射为精确的 6-DoF 位姿,实现对当前场景的物理 Grounding;后者则需要基于当前与过往的历史状态,连续做出多个决策以完成长期目标。

但是,真实世界的操作并非静态的空间问题,而是贯穿时间的连续过程。机器人不仅要抓得准,还必须记得住之前的关键状态,才能在长程任务中真正抓得对。这使得记忆机制成为连接空间操作与长程决策的关键能力。
受人类大脑「工作记忆」与「海马体」记忆机制的启发,作者团队还提出了 MemoryVLA,创新性地引入「感知 - 认知记忆」到 VLA,在决策时智能地从记忆库中「回忆」相关历史信息,实现时序感知的决策。更多信息可以参考:
论文:https://arxiv.org/abs/2508.19236 项目主页:https://shihao1895.github.io/MemoryVLA GitHub:https://github.com/shihao1895/MemoryVLA