[LG]《On Training in Imagination》N Timor, R Shwartz-Ziv, M Goldblum, Y LeCun… [Weizmann Institute of Science & New York University & Columbia University] (2026)
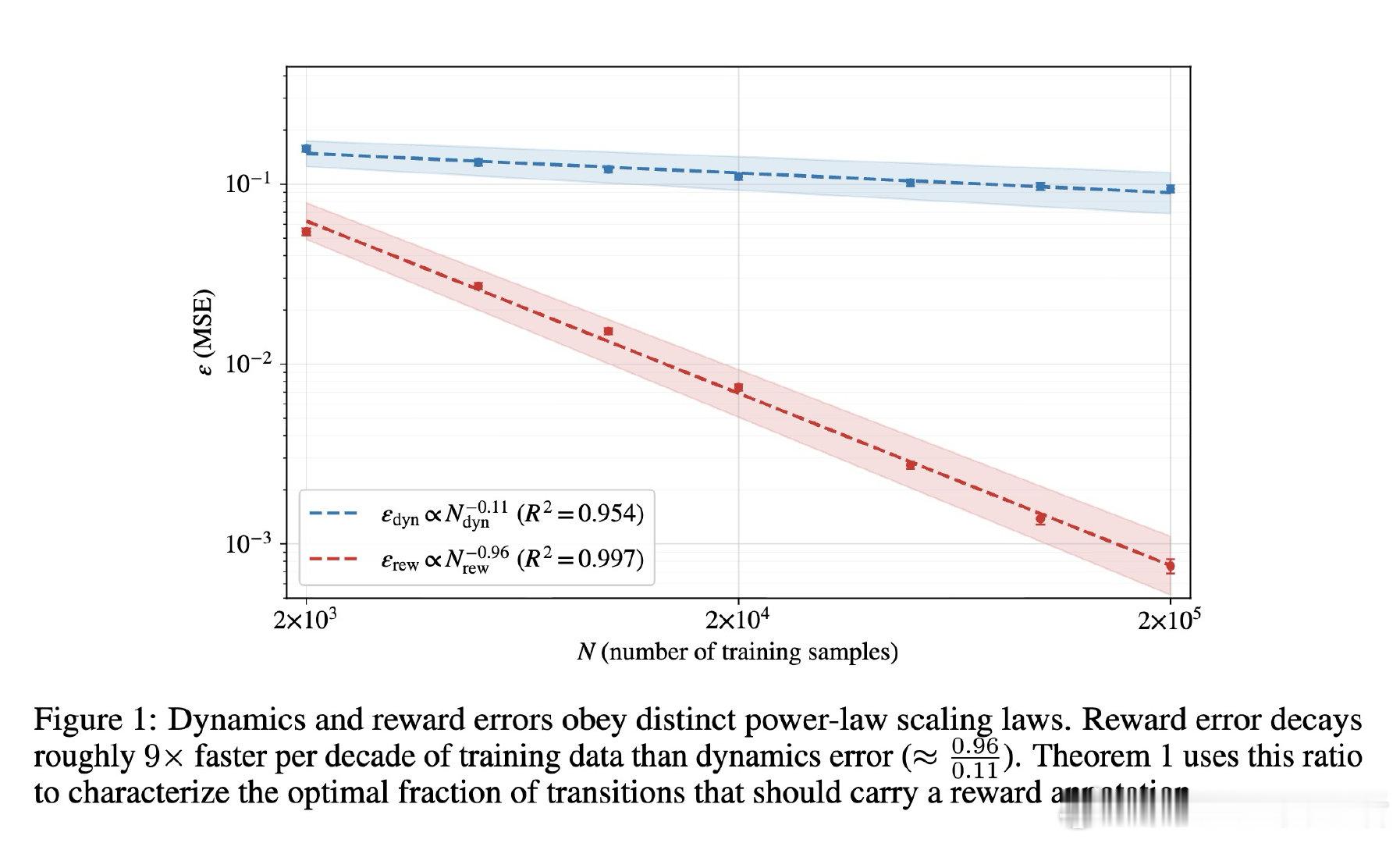
在模型化强化学习中,想象 rollout 的回报误差难以归因。过去方法把动力学与奖励误差揉成一团,本质原因是缺少可分配预算的误差账本。
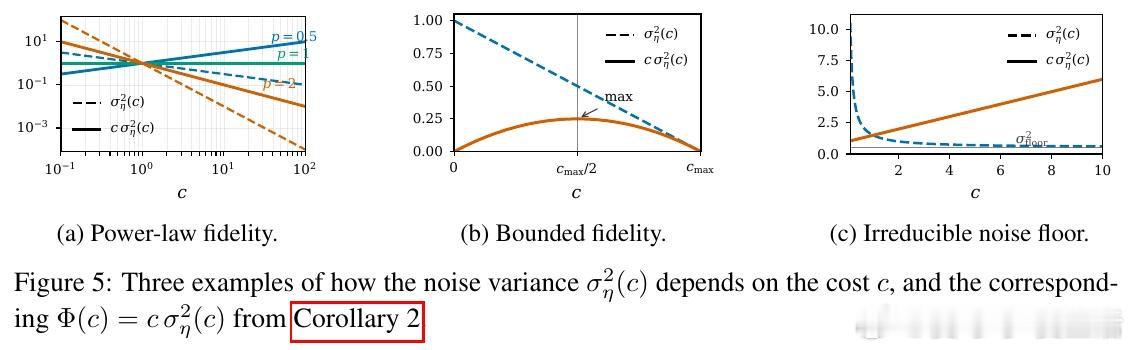
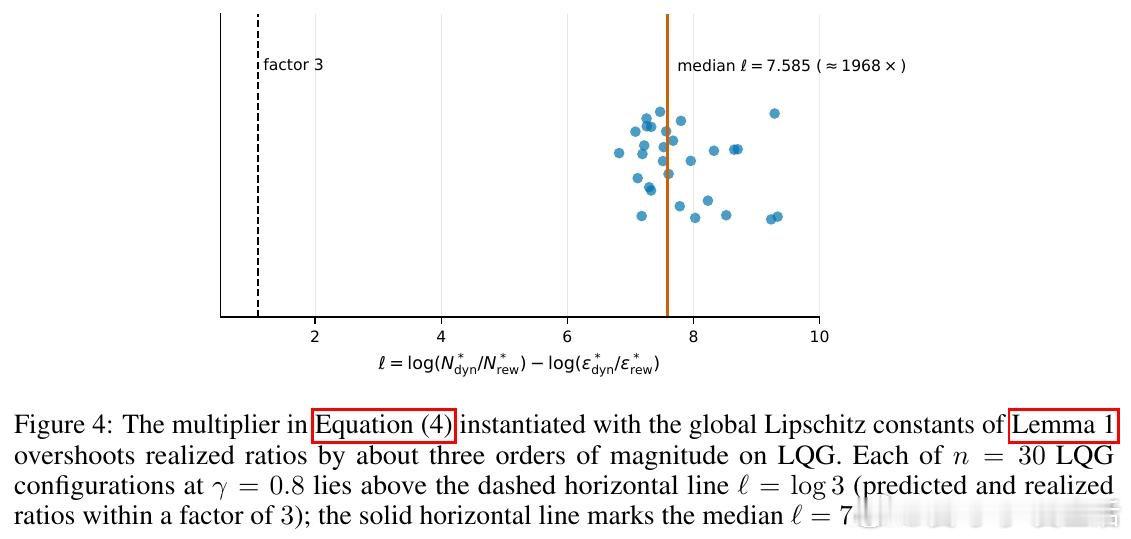
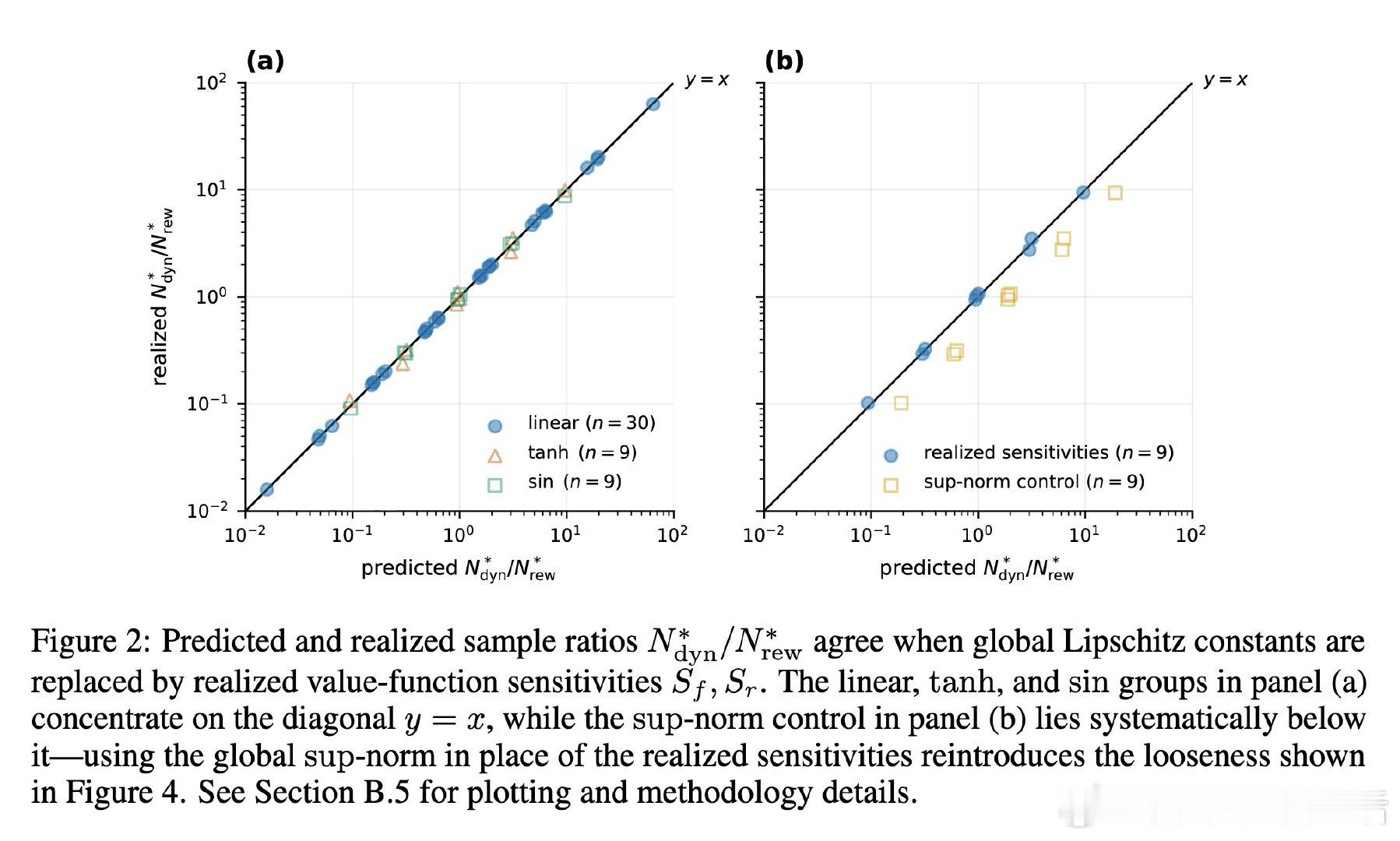
本文的核心洞见是:把奖励模型重新看作独立误差源。由此,用 Lipschitz 系数拆分回报差,并把样本成本、缩放律、噪声方差纳入同一优化,使预算选择可计算。
这项工作真正留下的遗产是训练想象的成本地图。它打开的新门是按误差衰减速度购买数据,但尚未跨过的门槛是全局 Lipschitz 界过松、随机环境仍未覆盖。
arxiv.org/abs/2605.06732 机器学习 人工智能 论文 AI创造营