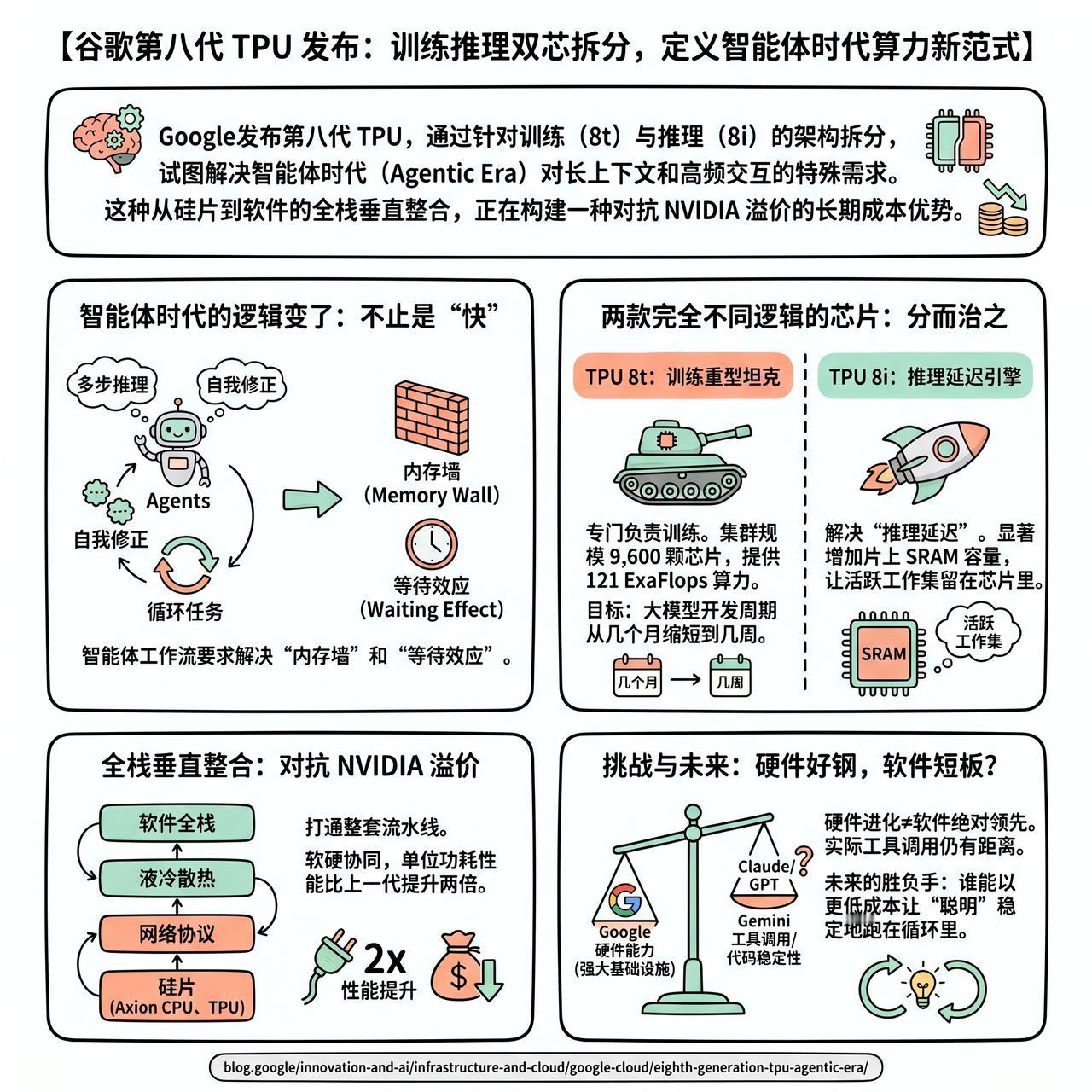
【谷歌第八代 TPU 发布:训练推理双芯拆分,定义智能体时代算力新范式】
快速阅读:Google 发布第八代 TPU,通过针对训练(8t)与推理(8i)的架构拆分,试图解决智能体时代(Agentic Era)对长上下文和高频交互的特殊需求。这种从硅片到软件的全栈垂直整合,正在构建一种对抗 NVIDIA 溢价的长期成本优势。
Google 正在把算力这门生意拆得更细。
以前我们觉得芯片就是算力,但到了智能体时代,逻辑变了。智能体不是在做简单的问答,它们在进行多步推理、自我修正,甚至是在一个循环里不断地执行任务。这种工作流对硬件的要求不再是单一的“快”,而是要解决“内存墙”和“等待效应”。
为了应对这种变化,Google 推出了两款完全不同逻辑的芯片。
TPU 8t 是个重型坦克,专门负责训练。它把单集群规模推到了 9,600 颗芯片,提供高达 121 ExaFlops 的算力。它的目标很直接:把大模型的开发周期从几个月缩短到几周。有网友提到,这种规模的算力储备,让 Google 在面对顶级模型训练时,具备了极高的容错率和效率。
而 TPU 8i 则是为了解决“推理延迟”而生的引擎。智能体在协作时,哪怕微小的延迟都会被放大成系统的卡顿。8i 显著增加了片上 SRAM 容量,目的就是为了让模型的活跃工作集能直接留在芯片里,别老是去翻慢吞吞的内存。
这种“分而治之”的策略,本质上是在利用垂直整合的优势。
当别人还在为买不到 GPU 或支付高昂的 NVIDIA 税发愁时,Google 已经把从 Axion CPU 到网络协议、再到液冷散热的整套流水线都打通了。这种软硬协同的深度,让它在单位功耗的性能上能比上一代提升两倍。
有观点认为,这种架构上的专业化,意味着 Google 正在试图定义智能体时代的底层协议。
不过,硬件的进化并不代表软件的绝对领先。有网友在讨论中指出,虽然 Google 拥有强大的基础设施,但在 Gemini 的实际工具调用(Tool Use)和代码执行稳定性上,目前与 Claude 或 GPT 相比仍有距离。这种“好钢用在刀刃上”的硬件能力,能否最终转化成产品端的统治力,还得看模型层能否补齐那块逻辑短板。
也许未来的胜负手不在于谁的模型更聪明,而在于谁能以更低的成本,让这些“聪明”稳定地跑在循环里。
blog.google/innovation-and-ai/infrastructure-and-cloud/google-cloud/eighth-generation-tpu-agentic-era/