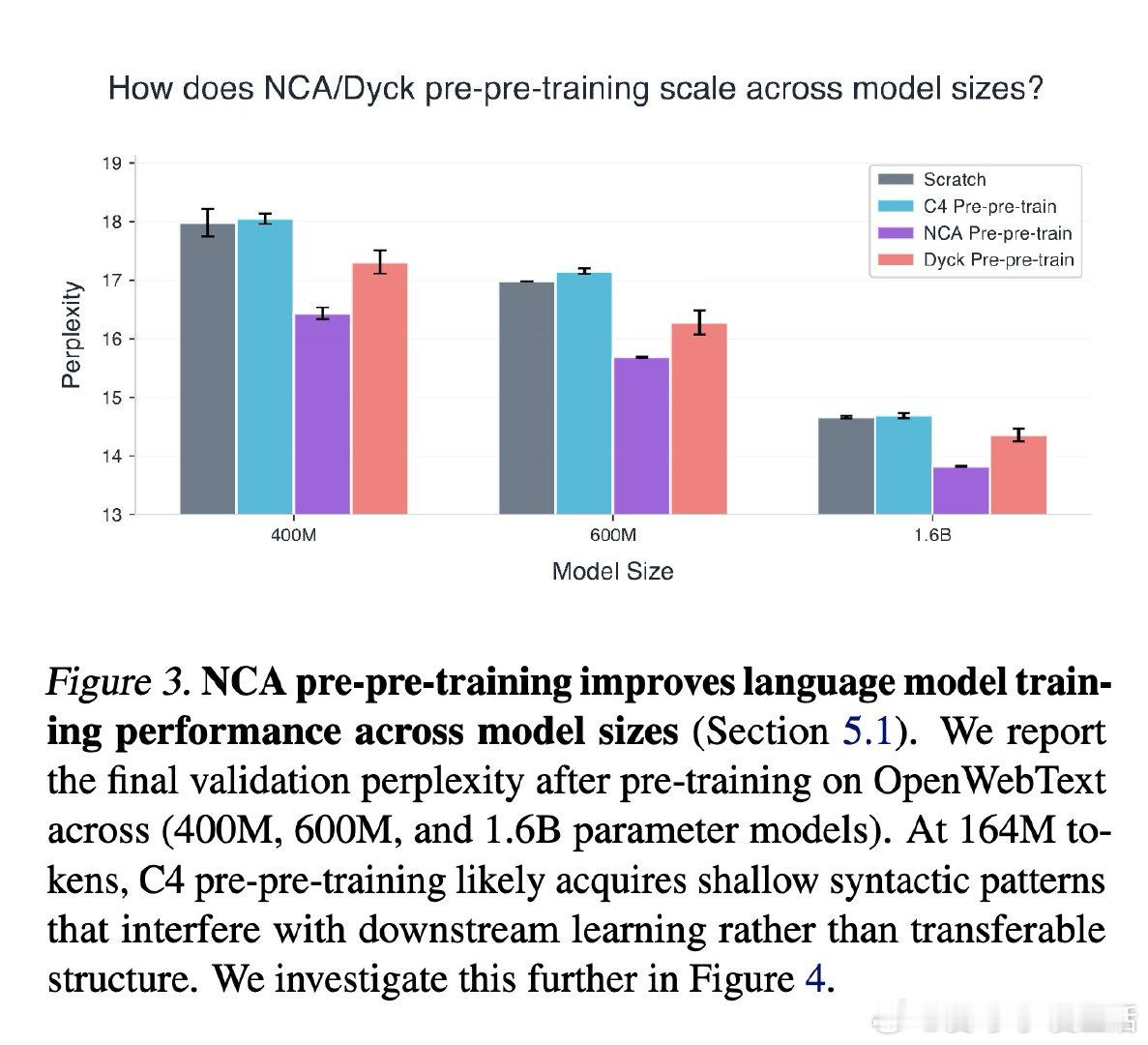
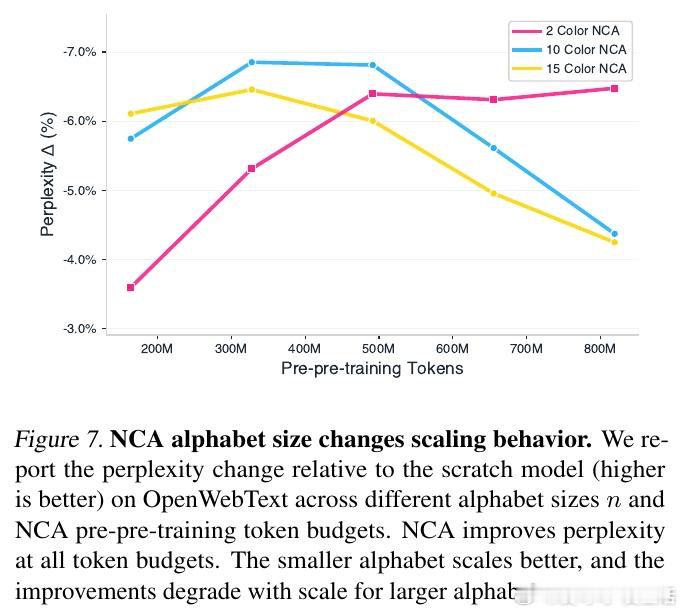
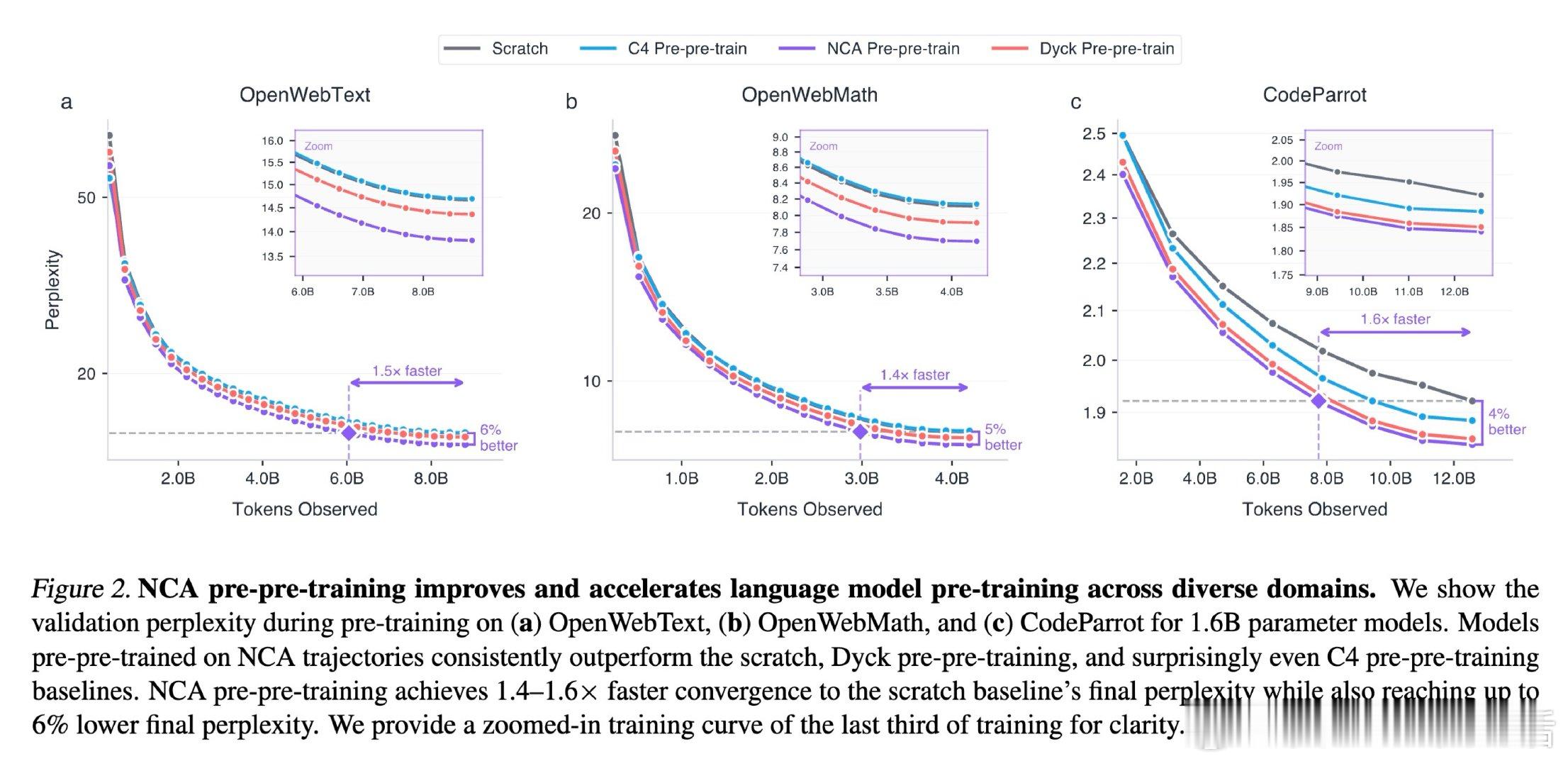
[LG]《Training Language Models via Neural Cellular Automata》D Lee, S Han, A Kumar, P Agrawal [MIT] (2026)
在高质量文本趋近耗尽的压力下,大语言模型的预训练正面临数据瓶颈——自然语言本身承载人类偏见、混淆知识与推理,且规模有限。过去的合成数据替代方案(随机字符串、简单算法任务)始终未能匹敌语言训练的效果,根本原因是这些数据结构单一、缺乏自然语言所具备的丰富统计特性。
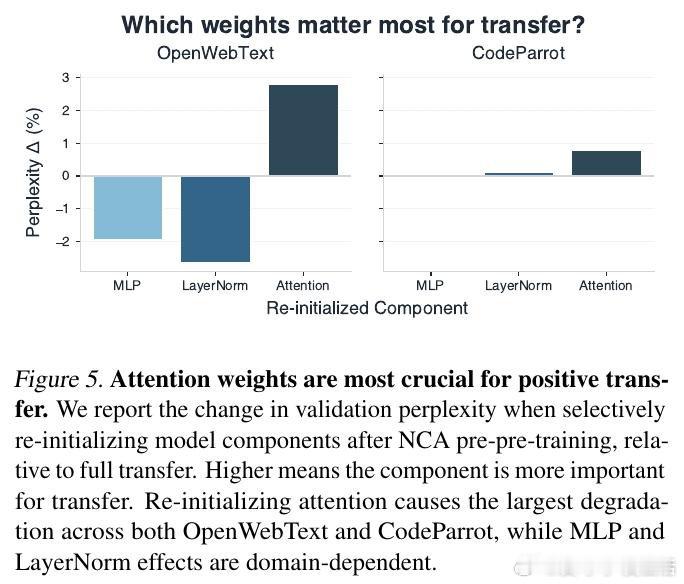
本文的核心洞见是:把"结构"而非"语义"看作智能涌现的真正基底。由此,用神经细胞自动机生成的时空动态序列作为预预训练数据,逼迫模型在每条序列中从上下文推断隐藏规则——这与大语言模型处理自然语言时所需的潜在贝叶斯推断机制高度一致。注意力层吸收了这一"规则推断"能力并完整迁移,而MLP层则编码领域专属知识,迁移效果因域而异。
这项工作真正留下的遗产是:合成数据无需语义内容,只需结构复杂度与目标域匹配,即可超越等量甚至十倍量级的自然语言预训练。它为后来者打开的新门是:通过调控合成数据生成器的复杂度,实现面向特定领域的精准预训练,可能催生更高效的专用小模型。但尚未跨过的门槛是:如何系统地将目标域所需的计算结构"翻译"为合成数据生成策略,现有的gzip压缩率和字母表大小仅是复杂度的粗粒度代理。
arxiv.org/abs/2603.10055
机器学习 人工智能 论文 AI创造营