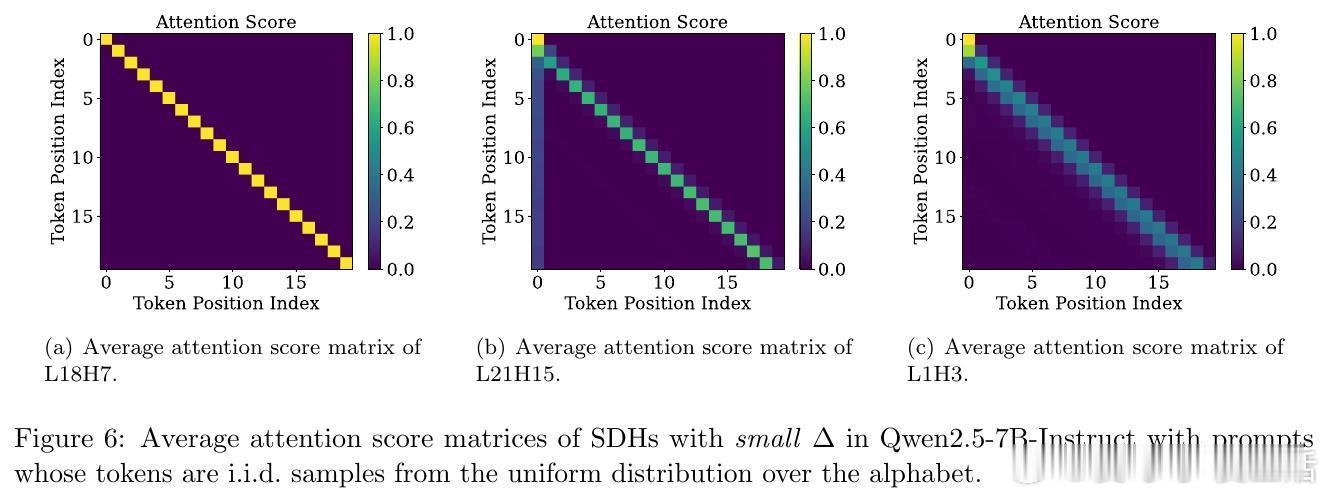
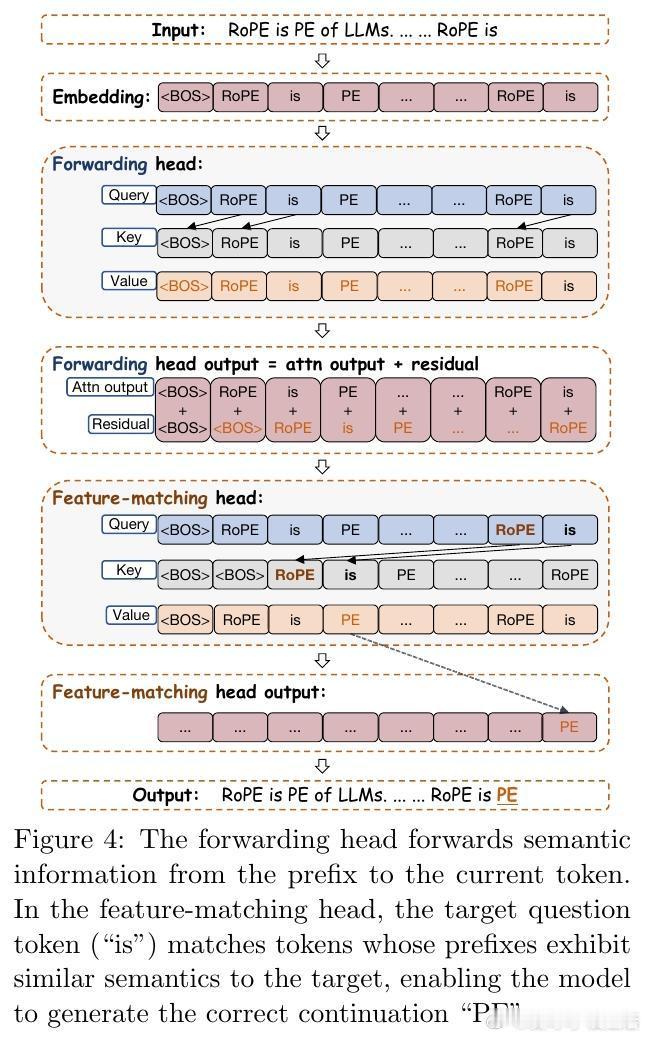
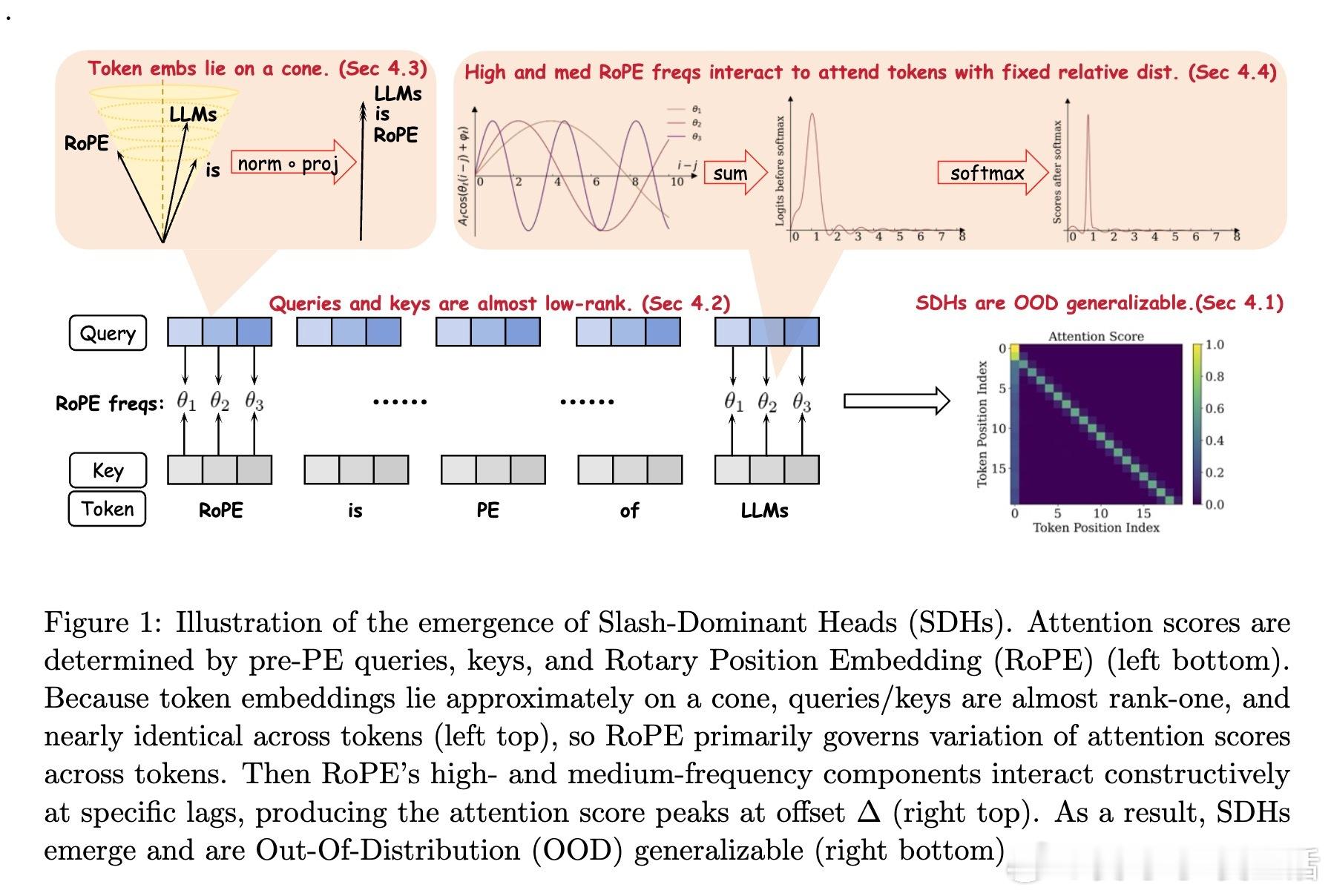
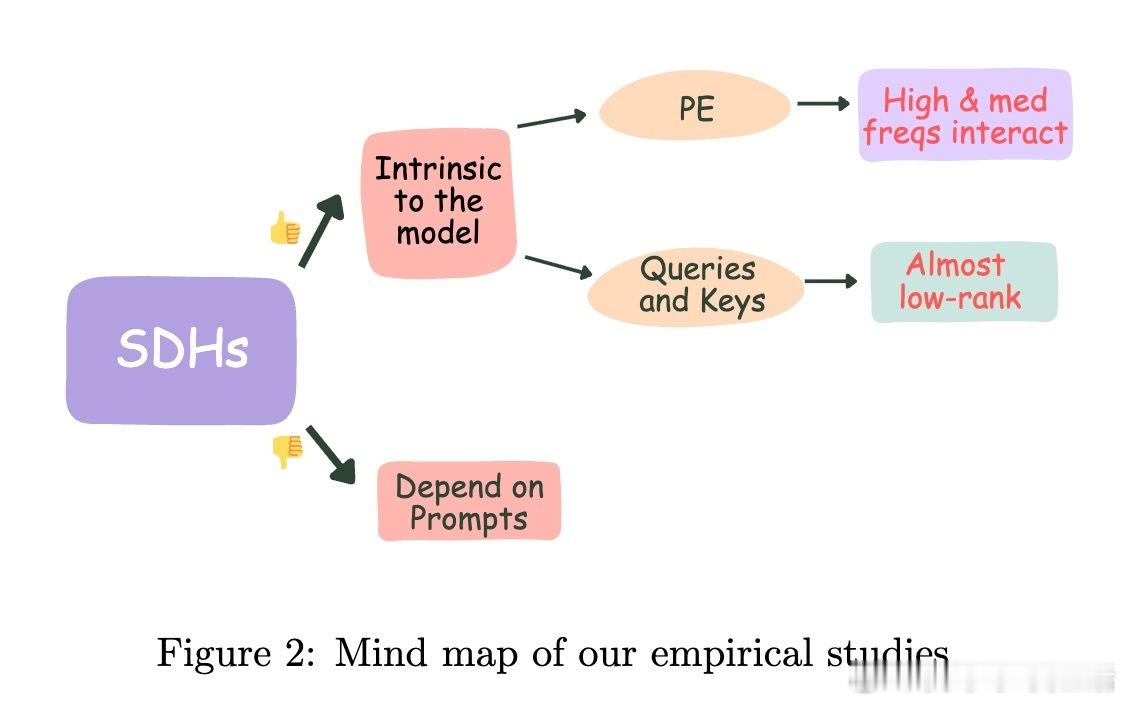
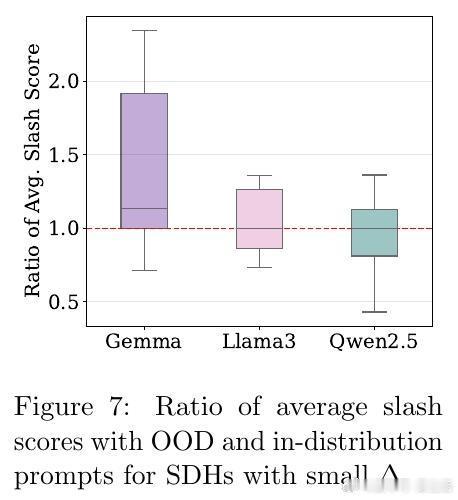
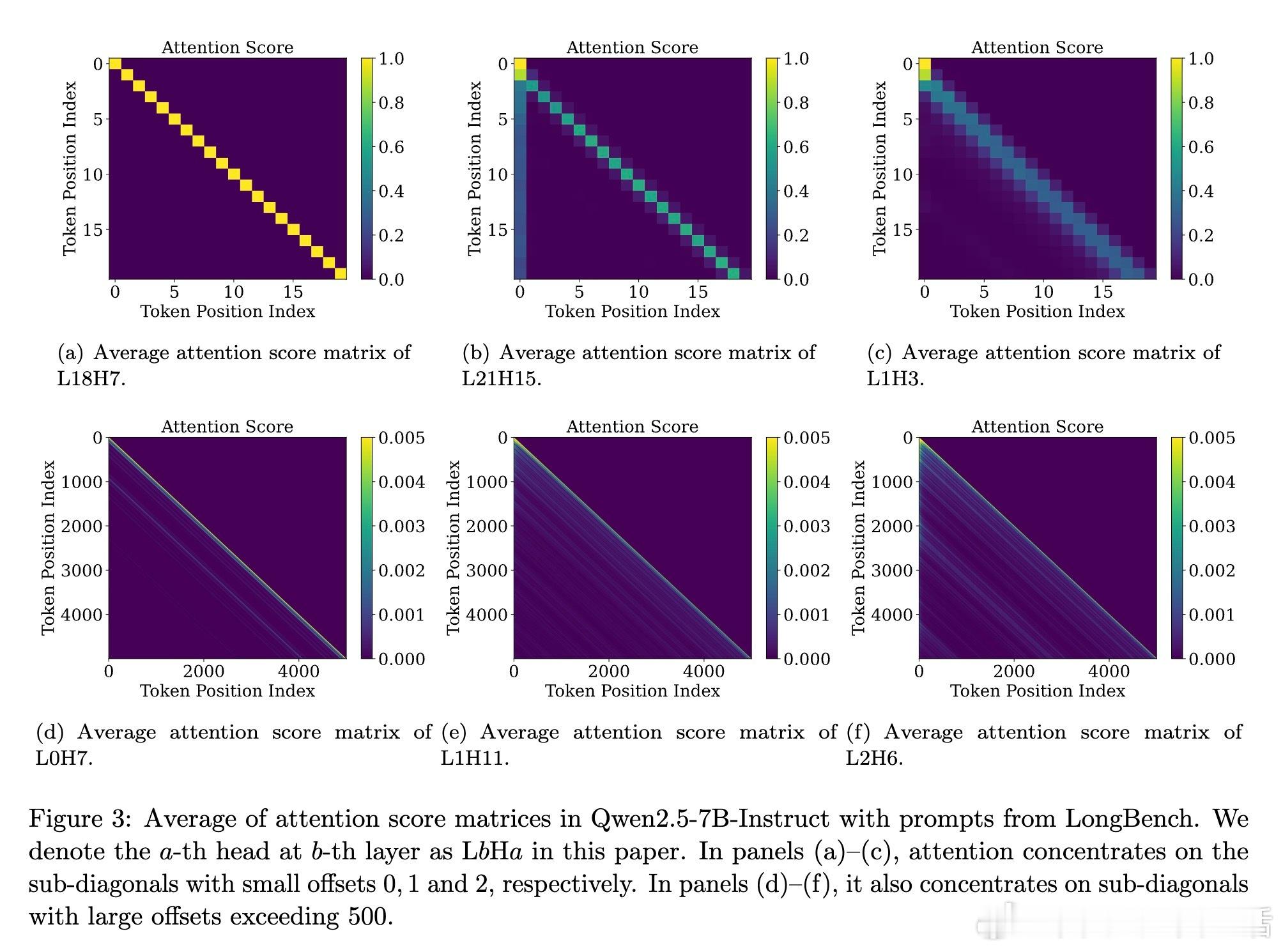
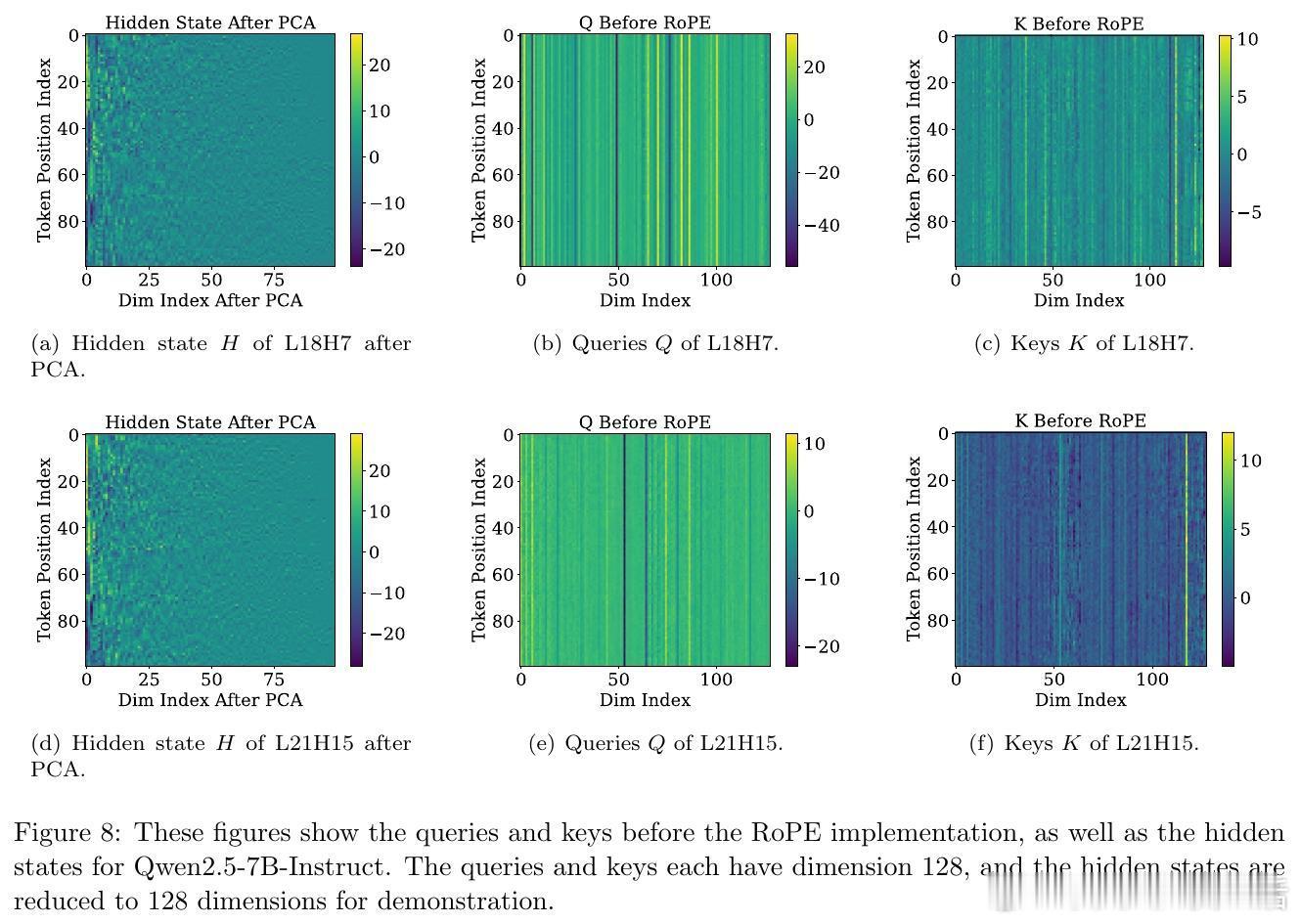
[LG]《Demystifying the Slash Pattern in Attention: The Role of RoPE》Y Cheng, F Zhang, Y Hou, C Du... [National University of Singapore] (2026) 大模型注意力机制中,那些神秘的斜线模式(Slash Pattern)究竟从何而来?当我们观察 Llama 或 Qwen 等大模型的注意力矩阵时,常会发现能量高度集中在某些特定的次对角线上。这种被称为“斜线主导头”(SDH)的现象,不仅是模型传递信息的关键回路,更是理解其内在逻辑的切入点。本文揭开了这一谜团:这并非巧合,而是旋转位置编码(RoPE)与模型几何特征共同演化的必然。1. 斜线模式是模型的“本能”,而非对输入的“反应”研究发现,这些斜线模式是模型固有的算法机制。即便输入完全随机、毫无语义的乱码,这些斜线依然清晰可见。这意味着 SDH 具有极强的分布外(OOD)泛化能力。它不是在处理特定的文本语义,而是在执行一种底层的、通用的信息传递协议。2. 语义的收敛与权力的交接为什么注意力会表现得如此整齐划一?秘密在于 Token 嵌入的几何结构。在主流 LLM 中,Token 向量实际上分布在一个圆锥体(Cone)上。这导致投影后的 Query 和 Key 矩阵在不同 Token 之间几乎是“秩一”(Rank-one)且近乎相同的。当语义信息的差异被刻意压缩,位置信息便接管了战场,主导了注意力的分配。3. RoPE 频率的精密共鸣既然 Query 和 Key 在不同 Token 间几乎失去了区分度,那么注意力的波动就全看 RoPE 的表演了。RoPE 的中高频组件在特定的偏移量下会产生相长干涉,精准地制造出注意力分数的峰值。正是这种频率间的协作,决定了模型在哪个距离上“搬运”信息。4. 梯度下降驱动的数学必然这不只是经验性的观察,更是数学上的必然。研究者通过对浅层 Transformer 的训练动力学分析证实:在梯度下降的作用下,只要满足 Token 圆锥分布和特定的 RoPE 频率条件,模型在训练过程中必然会演化出这种斜线模式。这是模型在优化路径上寻找到的高效信息传递方案。深度启发:语义退场之处,便是结构显现之时。斜线模式的本质,是大模型在极低秩的语义背景下,利用位置编码构建的一套高效索引系统。它告诉我们,模型在处理长文本时,有时并不关心“你说了什么”,而只关心“那个信息在什么位置”。这一发现为模型优化提供了全新视角:既然 SDH 的 Query 和 Key 具有明显的低秩特性,我们完全可以针对性地进行参数压缩,在几乎不损失性能的前提下,大幅提升推理效率。详情参考:arxiv.org/abs/2601.08297