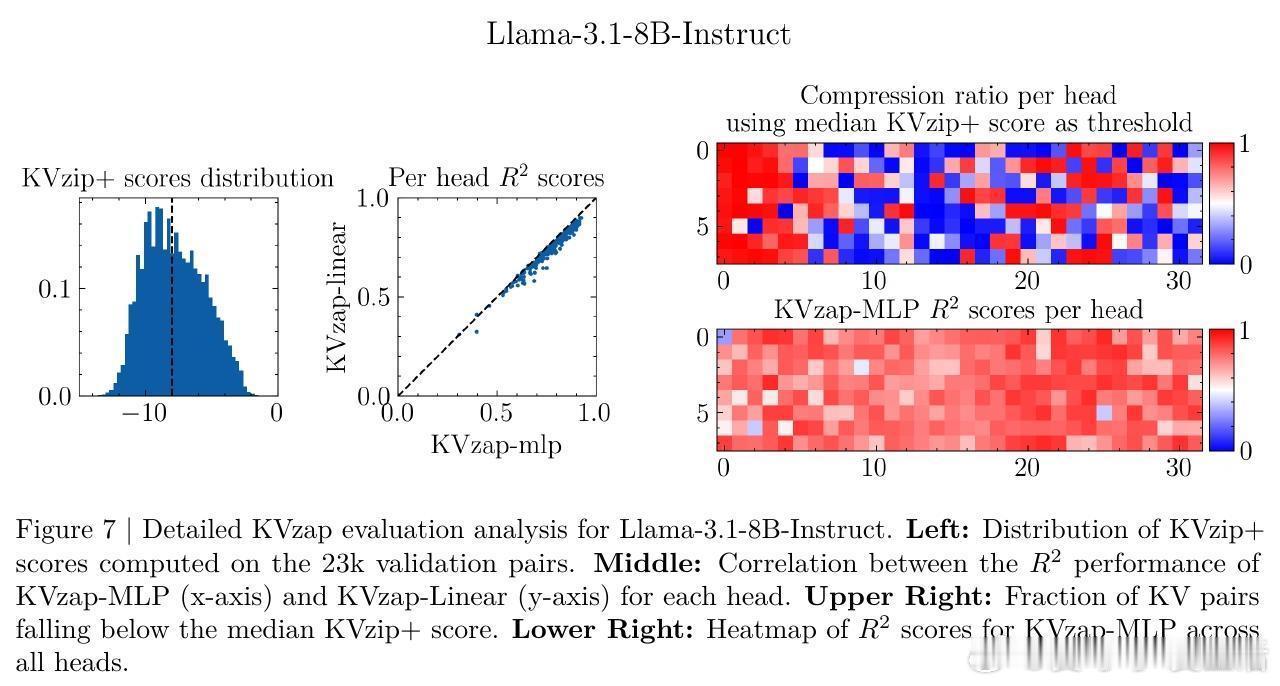
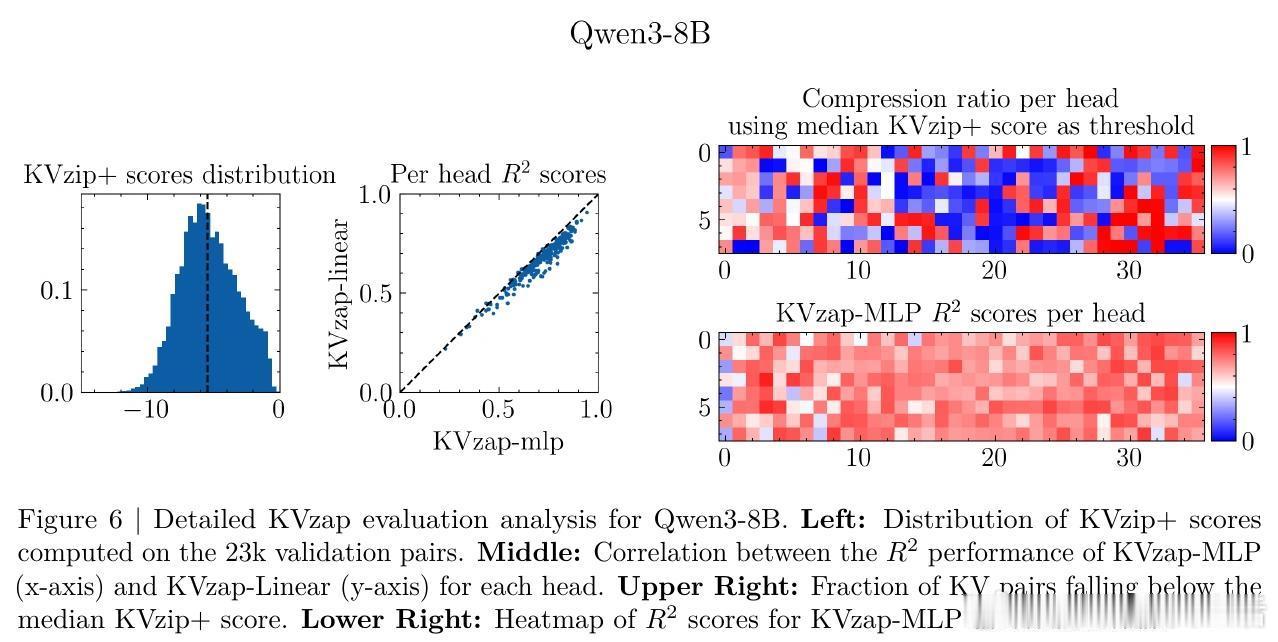
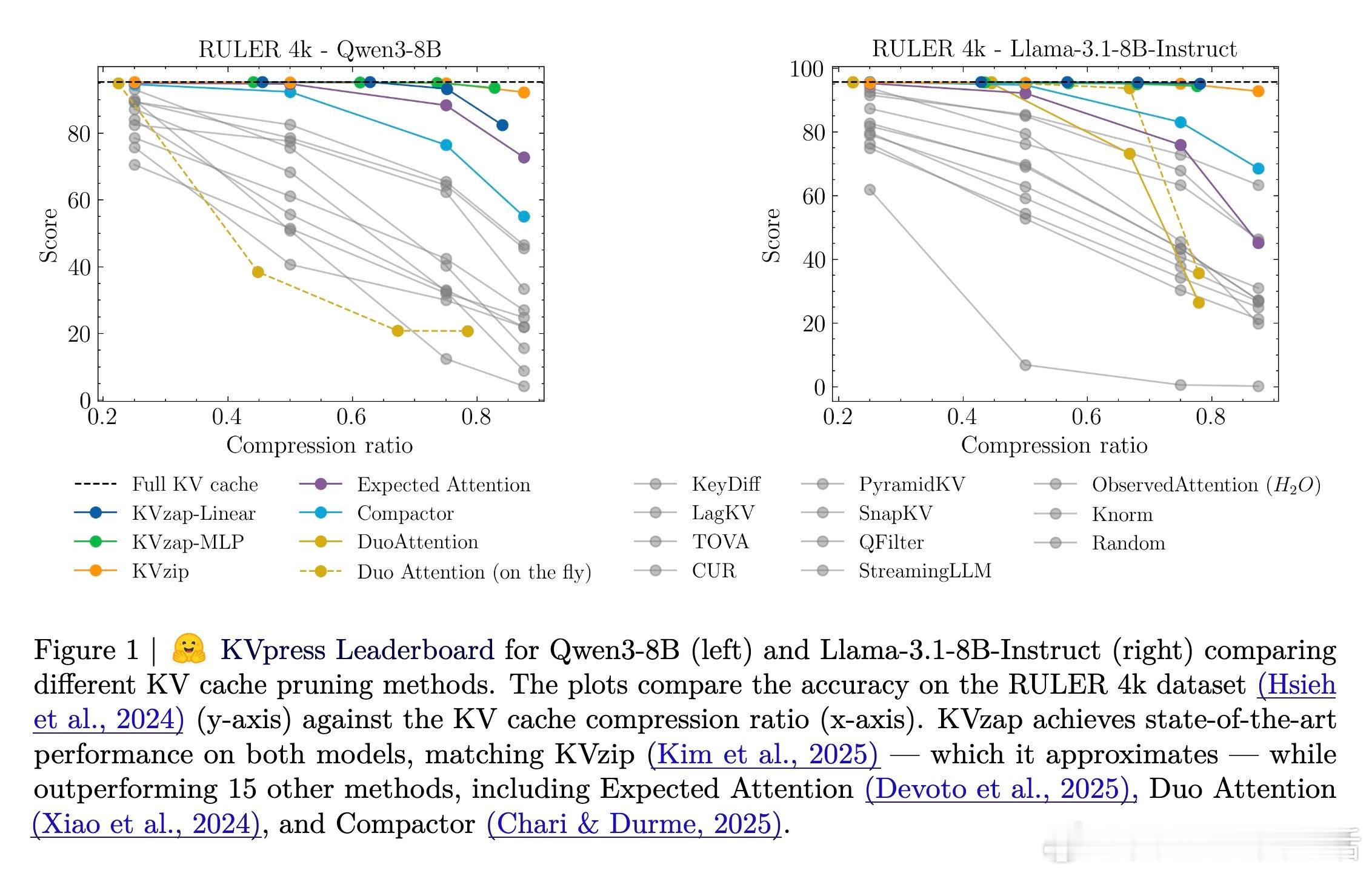
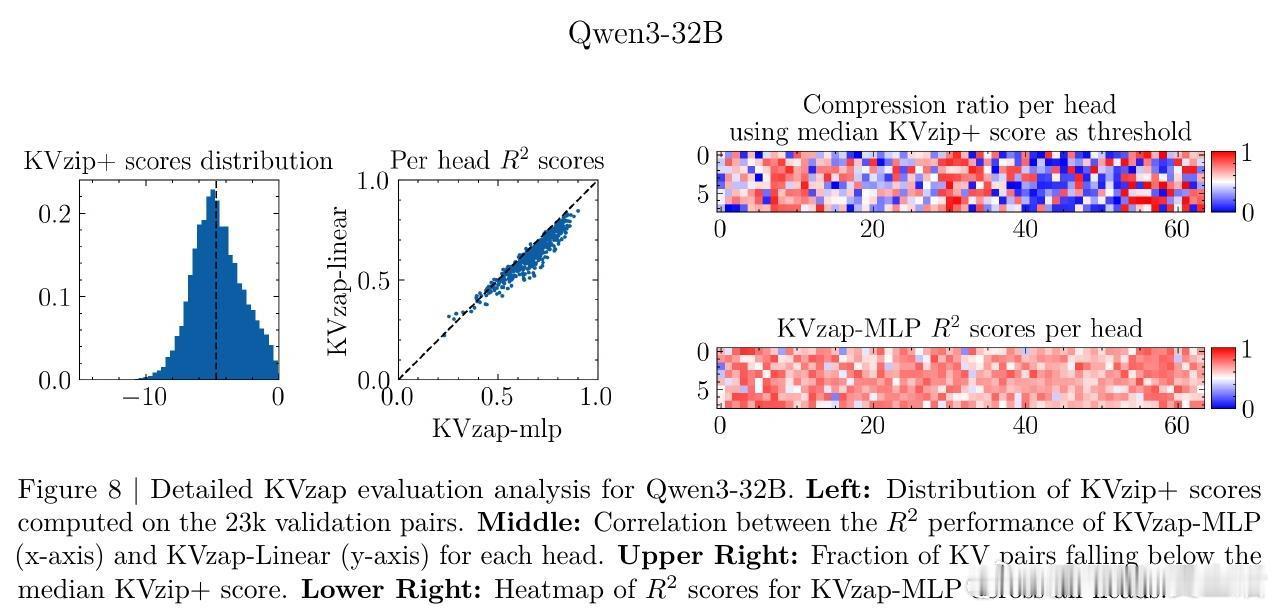
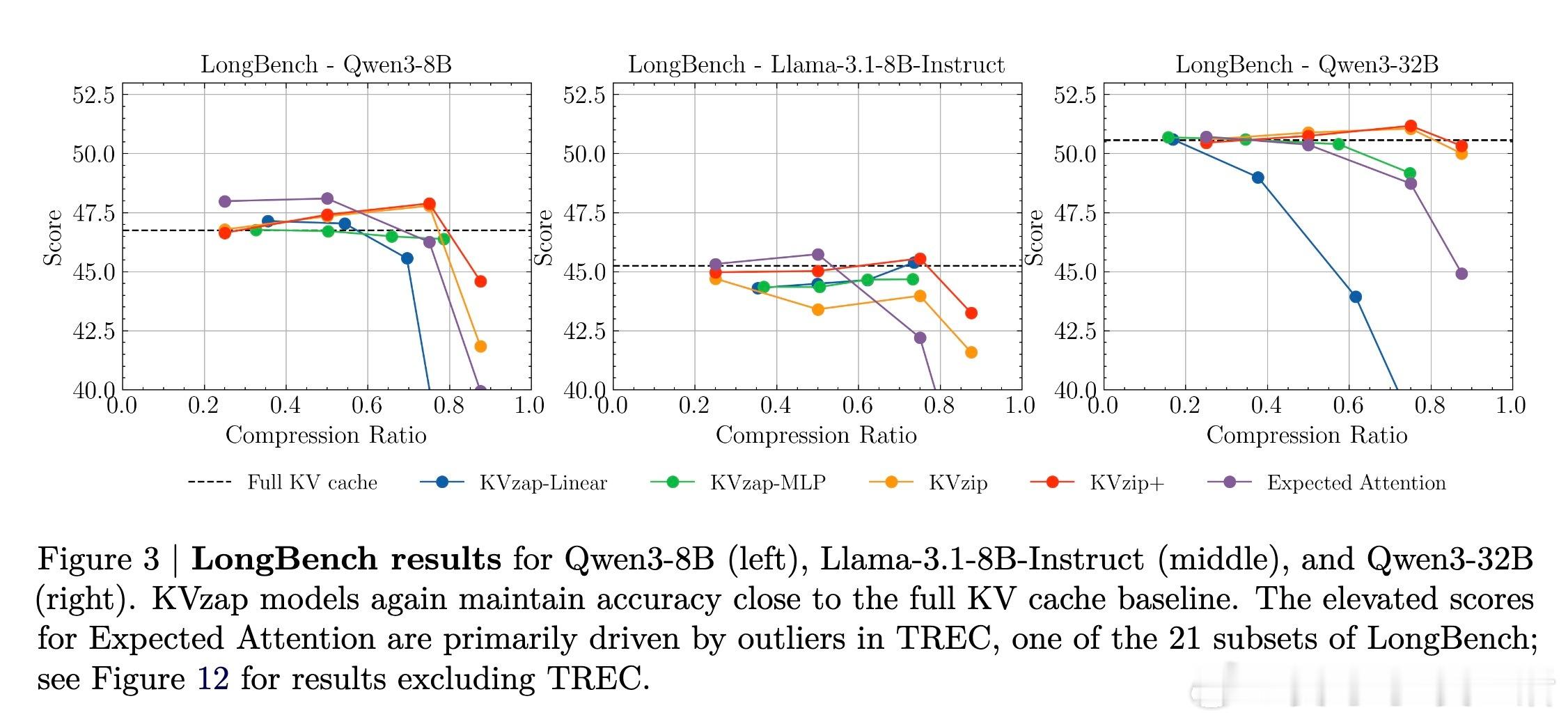
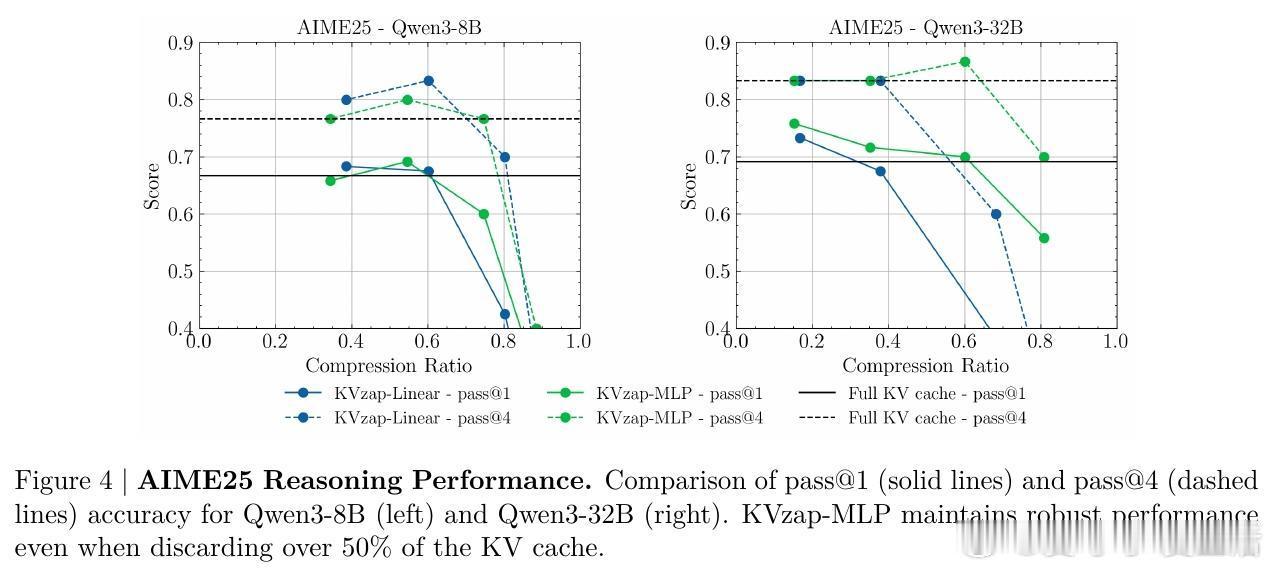
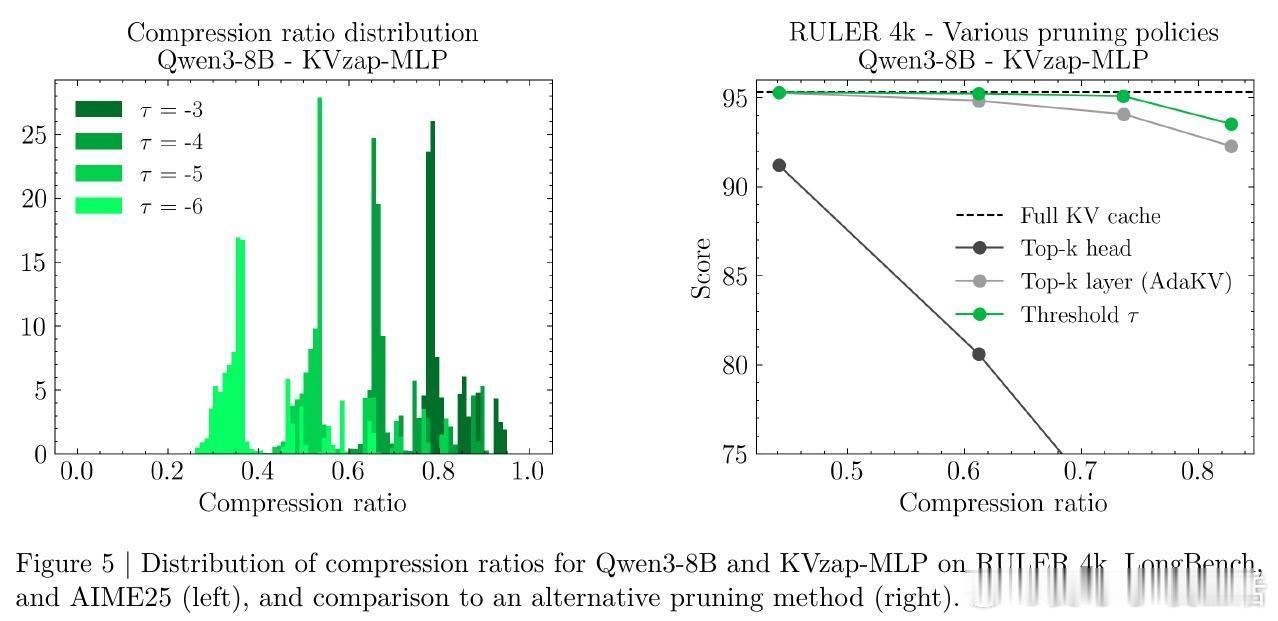
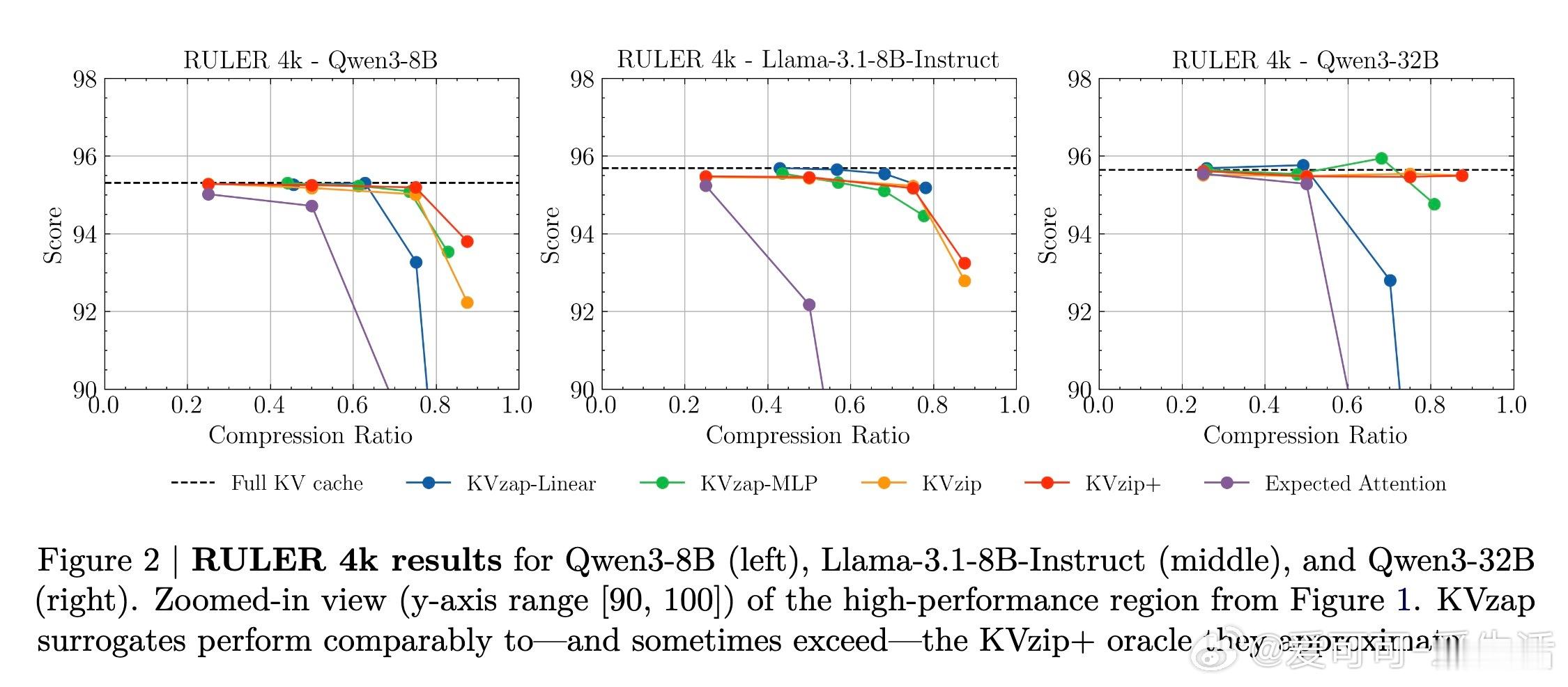
[LG]《KVzap: Fast, Adaptive, and Faithful KV Cache Pruning》S Jegou, M Jeblick [NVIDIA] (2026) 长文本时代,KV Cache(键值缓存)正成为大模型推理中沉重且昂贵的负担。随着上下文长度突破十万甚至百万级别,显存占用与延迟问题让推理引擎不堪重负。本文提出 KVzap,通过一种快速、自适应且忠实原意的剪枝方案,在 Qwen3 和 Llama-3.1 等主流模型上实现了 2 到 4 倍的压缩,且几乎没有精度损失。大模型推理的瓶颈不在算力,而在显存。在 Transformer 架构中,每一个生成的 Token 都会产生一组 KV 对。当上下文极长时,KV Cache 会占据绝大部分 GPU 显存,导致吞吐量下降。虽然业界已有许多剪枝方法,但往往面临速度与精度的两难境地:要么剪枝过程太慢,要么在推理阶段无法使用,或者干脆严重破坏模型表现。KVzap 的核心逻辑在于:并非所有信息都值得被永久铭记。就像人类阅读时不会对每个字都倾注同等注意力,模型处理文本时,某些 Token 的 KV 对在后续生成中几乎不再被访问。KVzap 改进了前作 KVzip 的评分机制,引入了 KVzip+,通过归一化项更精准地衡量每个 Token 对残差流的贡献。创新的关键在于引入了代理模型。传统的精准评分需要复杂的计算,甚至要跑两次预填充,这在生产环境中不可接受。KVzap 的天才之处在于,它训练了一个极轻量级的线性层或 MLP(多层感知机),直接根据隐藏状态预测重要性得分。这意味着模型在处理 Token 的瞬间,就能预判它是否值得被留在缓存中。动态阈值:让模型学会取舍。不同于固定比例的粗暴剪枝,KVzap 采用基于阈值的自适应方案。对于信息密度高的复杂指令,它保留更多缓存;对于冗余的重复文本,它则大幅压缩。这种灵活性确保了模型在处理 RULER、LongBench 等长文本任务,甚至是 AIME25 这种高难度推理任务时,依然能保持满血战力。极致的轻量化,几乎零开销。KVzap 的代理模型规模极小,计算开销仅占单层 Transformer 的 0.02% 到 1.1%。在实际推理中,这些微小的计算量完全可以被 GPU 的空闲周期覆盖。它不仅适用于预填充阶段,更首次完美适配了长文生成的解码阶段。深度思考:效率是通往智能的必经之路。KVzap 的成功再次证明,LLM 的 KV Cache 中存在巨大的冗余。我们不需要无限的内存,而需要更聪明的遗忘。当模型学会从隐藏状态中自我识别重要性时,它就离真正的低功耗智能更近了一步。总结:KVzap 为长文本推理提供了一个平衡速度、成本与精度的最优解。它不仅在 KVpress 排行榜上刷新了纪录,更通过开源代码为开发者提供了即插即用的工具。项目地址:NVIDIA/kvpress模型集合:NVIDIA/KVzap论文详情:arxiv.org/abs/2601.07891