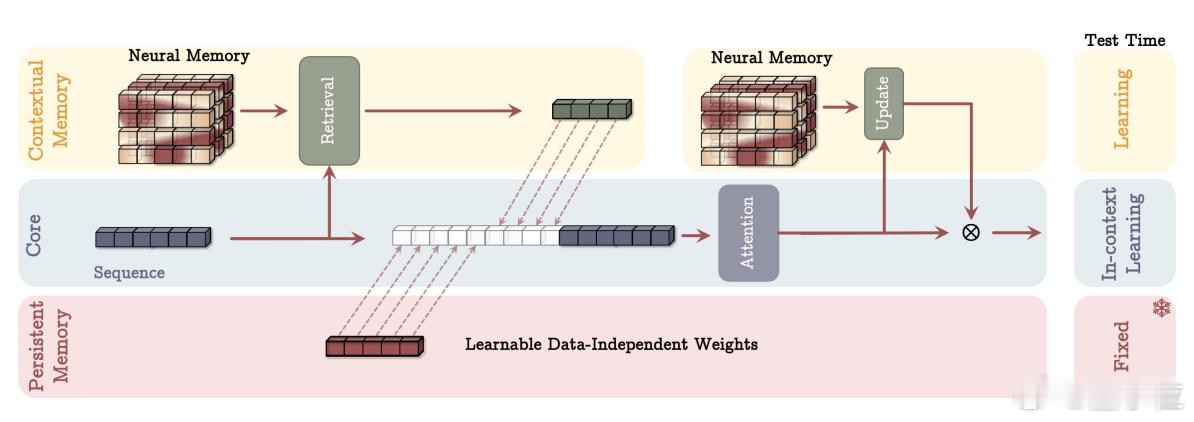
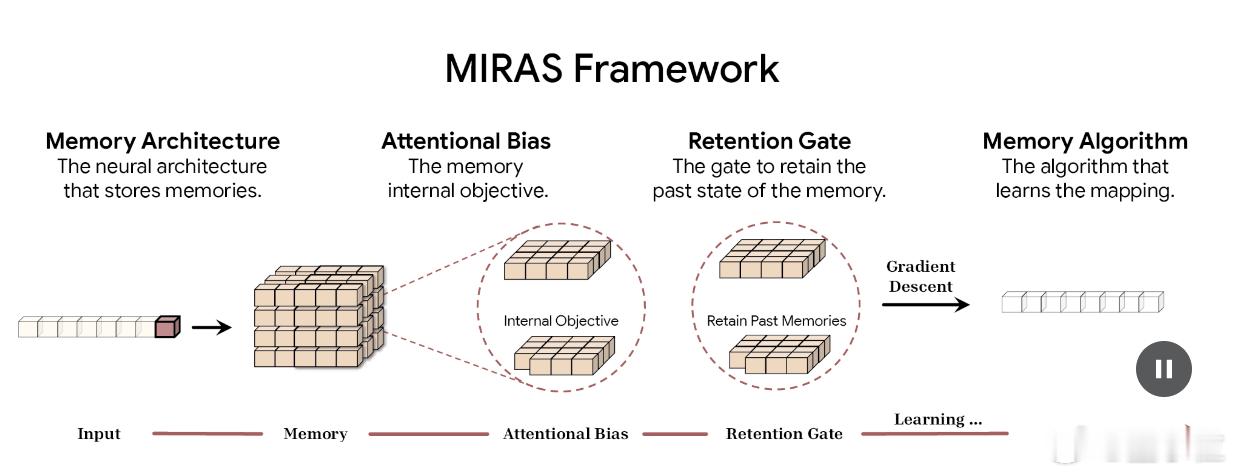
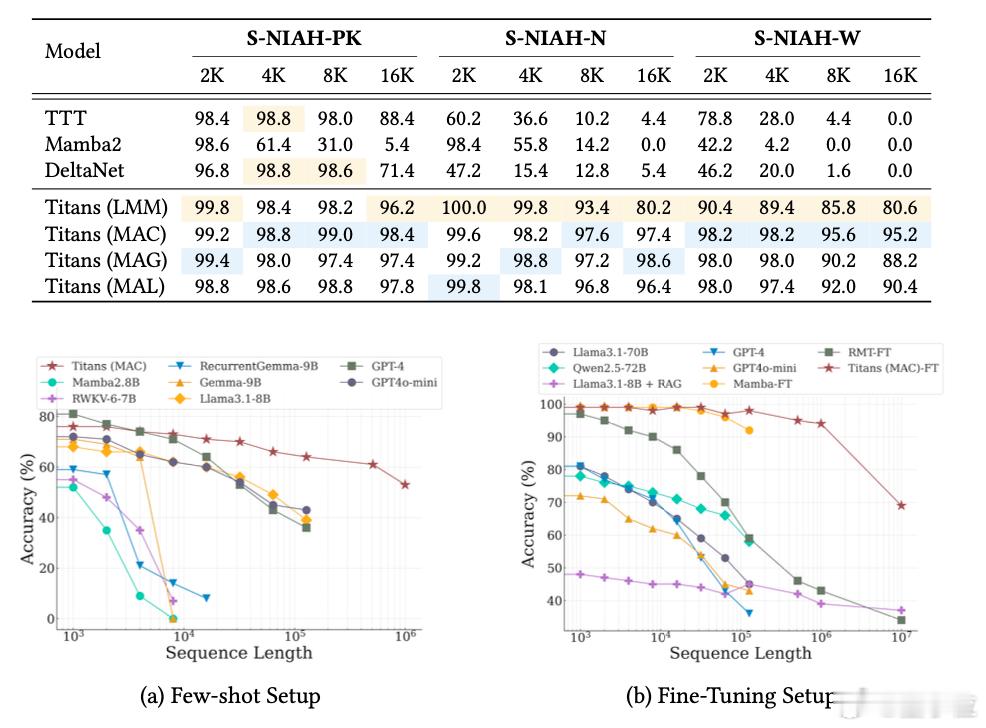
谷歌新架构突破Transformer超长上下文瓶颈 Transformer的提出者谷歌,刚刚上来给了Transformer梆梆就两拳(doge)。两项关于大模型新架构的研究一口气在NeurIPS 2025上发布,通过“测试时训练”机制,能在推理阶段将上下文窗口扩展至200万token。两项新成果分别是:- Titans:兼具RNN速度和Transformer性能的全新架构;- MIRAS:Titans背后的核心理论框架。核心要解决的,就是Transformer架构在处理超长上下文时的根本局限:计算成本会随着序列长度的增加而猛增。不得不说,从Nano Banana到Gemini 3 Pro,再到基础研究方面的进展,谷歌最近一段时间就是一个穷追猛打的架势。也难怪奥特曼要给OpenAI拉“红色警报”了。论文链接: 网页链接网页链接网页链接