还在对着海量病历手动摘抄、反复校对?
还在为文本不规范、信息难提取、科研建库慢而发愁?
上海藤核智能科技有限公司HoloData智能专病数据库管理平台重磅核心组件 ——专病库自然语言处理智能体正式上线!依托医疗大模型与深度学习技术,可将入院记录、病程记录、出院小结、检查报告、病理文书等非结构化医疗文本,一键转化为标准、可查、可分析的高质量数据资产,全面助力临床科研提速、提质、提效。
直击医疗文本处理核心痛点
医院日常产生大量病历、报告与随访记录,其中约80%为非结构化文本,普遍面临以下难题:
人工提取效率低、易漏项、易出错
术语不统一、格式不标准、数据难以复用
科研建库周期长、队列构建效率低
数据质量参差不齐,影响统计分析与成果产出
藤核专病NLP Agent,以AI技术打通医疗文本价值转化 “最后一公里”。
四大核心能力,精准适配医疗场景

1
医学实体识别,准确率超94%
自动从病历中精准抽取疾病名称、症状体征、药品、检查检验、手术操作、病灶信息、评分量表、时间节点等关键信息,覆盖2000+医学实体类型,关键信息不遗漏。
2
智能分词+词性标注,适配医疗复杂表述
支持中英混合、专业缩写、医学术语、长难病历文本处理,比通用NLP更懂医疗、更贴合专病科研需求。
3
关键词/实体双提取,百万医疗语料支撑
基于医学知识图谱实现语义精准筛选,自动提炼核心信息,科研关键变量一键获取。
4
新词发现闭环,持续迭代更精准
自动挖掘专病新词、罕见病术语、新疗法名称,动态扩展专业词库,持续提升识别精度。
全流程自动化:
从文本到数据,一步到位
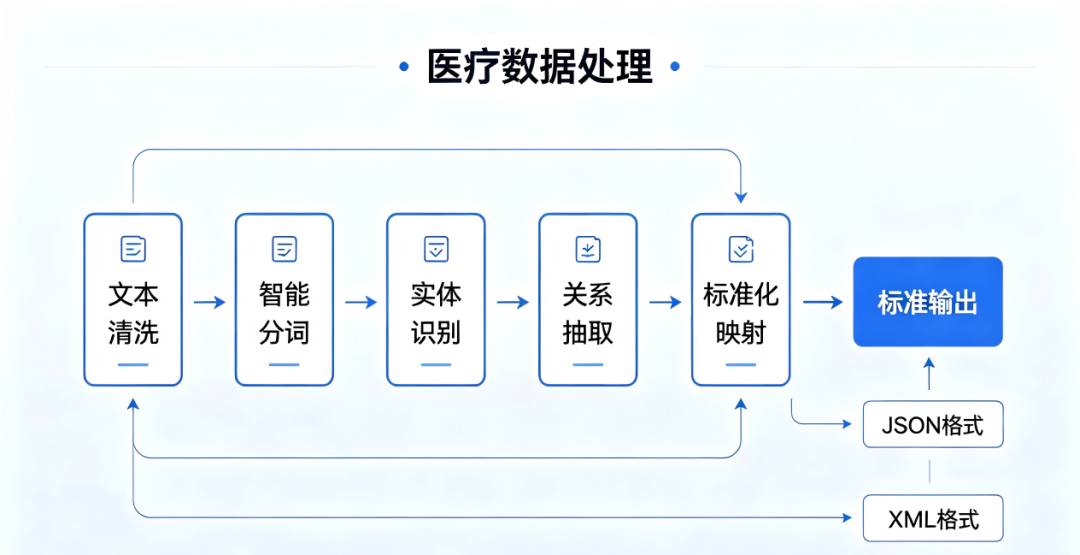
藤核专病NLP Agent打通文本清洗→智能分词→实体识别→关系抽取→标准化映射→标准输出全链路,支持JSON、XML、可视化多格式导出,可无缝对接:
专病数据库
数据统计分析平台
大型人群队列研究管理平台
专病库随访管理平台
科研报表与论文数据体系
真正实现:原始病历→标准数据→科研成果一键贯通。
全角色覆盖,适配全院科研场景
✅ 临床医生/科研人员:病历快速结构化,高效建库、构建队列、开展统计分析
✅ 数据工程师:批量ETL处理、自动化数据清洗与治理
✅ 系统管理员:专业词库维护、权限管理、系统稳定运行
✅ 科研管理部门:可视化报表呈现,快速洞察数据质量与科研进展
选择藤核专病NLP Agent的核心优势
✔医疗大模型原生训练,深度适配专病领域
✔对齐OHDSI国际标准,支持数据共享与复用
✔全流程数据质控,输出数据规范、可信、可用
✔24小时Token自动刷新,系统稳定不掉线
✔开箱即用,兼容Chrome、Edge、Firefox、Safari等主流浏览器
✔深度融入HoloData八大子平台,构建专病库全流程闭环
在公立医院高质量发展与临床科研创新提速的当下,数据已成为核心生产力。藤核智能专病库自然语言处理智能体,让每一份病历都成为可挖掘、可复用、可转化的高价值科研资产,助力医院高效产出科研论文、快速推进科研课题、加速临床成果转化。以AI赋能医疗科研,让数据创造真实价值。