
在质量管理领域,Cpk达到1.33通常被认为是流程“有能力”的黄金标准。这是一个我们都熟知的基准。但一个问题随之而来:如果1.33已经足够好,为什么像苹果、丰田这样的顶尖制造商,以及许多要求严苛的客户,会坚持要求Cpk达到1.67,甚至2.0(即六西格玛水平)?
答案并不在于我们统计过程控制(SPC)图表上能看到的数据,而在于那些我们无法及时看到的风险。更何况,在真实的生产环境中,仅凭图表上的数据点,操作员几乎不可能将流程做到理论上的完美居中。我们必须为这种不可避免的微小偏差和潜在的漂移预留空间。本文将揭示满足于“刚刚好”的Cpk标准背后,潜藏的巨大风险。
核心洞察一:流程早已偏移,图表却悄无声息理解这个问题的核心在于认识到一个根本性的挑战:在生产现场,我们永远无法看到一个完美的“正态分布”曲线,我们看到的只是SPC图表上一个个独立的、离散的数据点。
这就引出了“1.5西格玛检测延迟”的核心概念。简单来说,为了让我们的统计工具有足够的把握确认一个流程的均值发生了偏移,这个均值通常需要移动1.5个标准差(Sigma)。在此之前,任何异常数据点都极其罕见,以至于在统计上无法与正常的随机波动区分开来,最终被淹没在数据的“噪音”中。
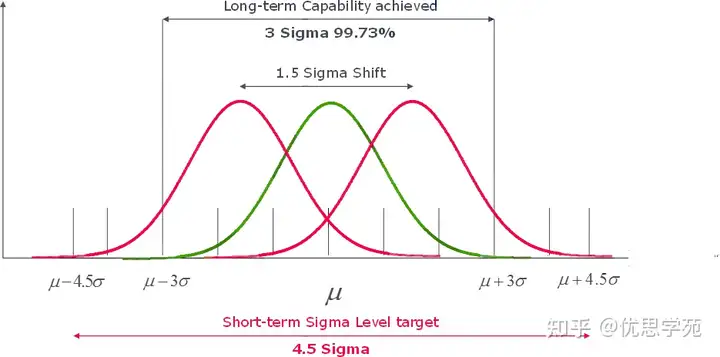
要想确信一个流程已经发生了移动,其整个分布曲线必须平移整整1.5个标准差。只有到那时,异常数据点才会足够频繁地出现,从而被我们的统计工具可靠地检测到。
核心洞察二:Cpk 1.33——一场你可能输掉的赌博那么,当这个1.5西格玛的检测延迟与Cpk 1.33的流程相遇时,会发生什么?
首先,我们必须清楚Cpk 1.33在视觉上意味着什么:它意味着你的流程分布(±3西格玛)与规格上限(USL)和规格下限(LSL)之间,只有1个标准差的“缓冲空间”。
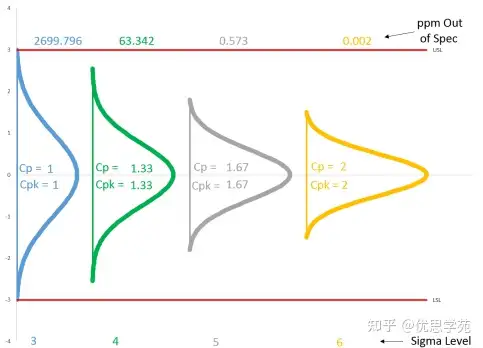
更糟糕的是,Cpk 1.33流程的标准差本身就比较大。这意味着1.5西格玛的漂移不仅是一个统计概念,更是一次距离上相当可观的实际偏移。在你的图表发出警报前,流程可能早已“漂”出千里之外。
现在,将这两个概念结合起来:想象一下,这个“合格”的流程,在被我们的图表检测到之前,悄无声息地发生了1.5西格玛的偏移。由于它最初只有1个西格玛的缓冲空间,1.5西格玛的偏移意味着其分布的尾部现在已经远远超出了规格界限。
其后果是一场灾难性的、无声的失败:你的流程正在持续生产、甚至可能已经交付了大量的不良品,而你的控制图却依然告诉你一切正常。
核心洞察三:更高的Cpk,是你的“防漂移”安全网这正是为什么行业领导者追求更高Cpk的根本原因。要求Cpk达到1.67或2.0,并不仅仅是为了追求更小的变异,更关键的是为了建立一个能够吸收“未被检测到的流程偏移”的强大安全网。
场景一:Cpk 1.67 该流程拥有2个西格玛的缓冲空间。当发生1.5西格玛的偏移时,其分布的尾部虽然逼近边界,但仍被安全地控制在规格界限内(还留有0.5西格玛的余量)。缺陷被成功拦截。
场景二:Cpk 2.0 (六西格玛) 该流程拥有高达3个西格玛的缓冲空间。即使在经历了1.5西格玛的严重偏移后,它的分布距离规格界限依然非常遥远,处于绝对安全区。
这里有一个最强有力的结论:一个已经偏移了1.5西格玛的六西格玛流程,其能力和产生的不良品率,仍然优于一个完美居中的Cpk 1.33流程。这就是顶级制造企业坚持更高Cpk标准的终极逻辑。
结论:从被动监控到主动预防总而言之,对更高Cpk(如1.67或2.0)的要求,并非不切实际的“过度设计”,而是一种极其务实的风险管理策略。它旨在构建一个有弹性的、强大的生产流程,能够从容应对现实世界中统计检测工具的固有局限性。
这代表了质量管理的思维跃迁——从仅仅监控流程,转变为主动确保零缺陷的交付。
现在,你该如何审视那些Cpk为1.33,且被你标记为“安全”的流程?它们真的是安全的吗,还是正在无声生产缺陷的定时炸弹?