【爆点】2025年7月,Google将5000小时的医疗语音,数据输入一个仅含1亿参数的小型模型,结果令人震惊同样使用一

【爆点】2025年7月,Google将5000小时的医疗语音,数据输入一个仅含1亿参数的小型模型,结果令人震惊同样使用一张RTX4090显卡,Whisperv3Large在放射科口述测试中出错14次,而MedASR仅出错12次,换句话说,前者把阿莫西林识别成了阿莫仙,后者却准确区分了毫克与毫升。

【事件还原】把时间回溯到发布当天,MedASR在HuggingFace上线才仅仅48个小时,下载量就一下子猛增到了12k,比榜单排名第二的整整,3倍的差距。有意思的情况在于,模型卡上标注着单卡8G显存可运行,好几个医院的CIO直接@自己家的IT并且说,“来尝试一下,更夸张的是,在RAD-DICT测试集上,Whisperv3Large的WER是25.3%,而MedASR直接降到4.6%,好像是将错误率重重地压了下来。【技术分析】三层蛋糕训练法,底层接触通用语音,中层学习医疗对话,顶层掌握科室黑话
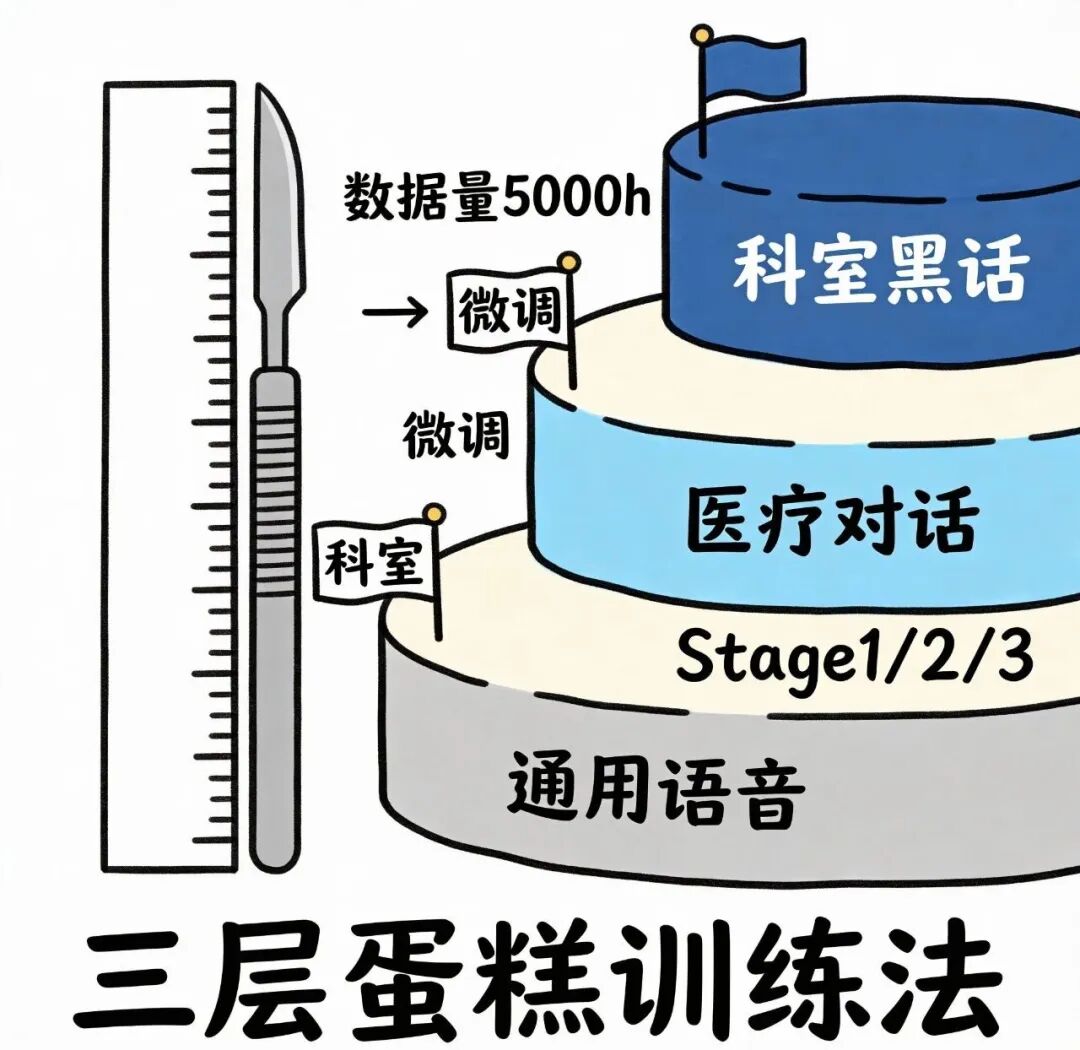
关键之处在于共享因子分解,简易来讲,也就是把参数当作积木,将重复运用的先组合成底座,专门的部分再开展插拔。对比着来看,Whisper那种一锅炖就好像让老板同时管理财务、清洁还有做手术一样,不出差错才是奇怪的事情。在数据端方面,Google先是拿5000小时医疗音频来开展预训练,随后用科室专属语料去进行微调,药品名识别的F1值提高到了0.96,RTF小于0.3,实时转写就连喘气声都给你分割成标点。【痛点速写】听错药名堪称医疗安全的0日漏洞,国内三甲医院的调研数据显示,21%的处方调整源于口头转录错误,换句话说,每五张处方中就有一张靠猜完成,更棘手的是,由于法规要求数据不得出境,即便云端大模型再先进,医院也只能望而却步。
【性能证据】
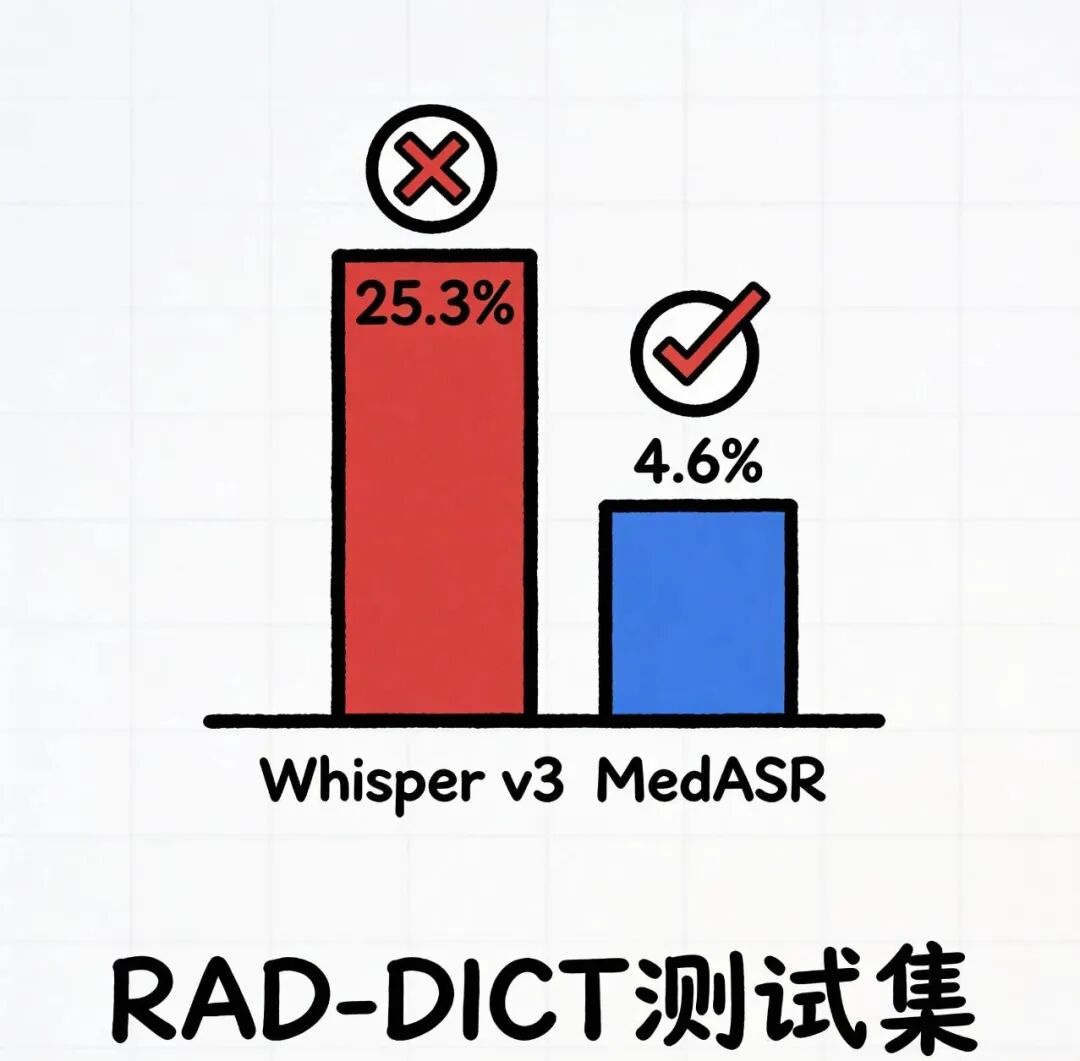
数据不会骗人从25%降到了4.6%,这便是专模对于通模的降维打击,药品名、拉丁词根、剂量单位,MedASR一下子就辨认出来了,一点差错都没有,而Whisper却会把头孢他啶写成头泡他定,护士看到后直接一脸疑惑。

【落地挑战】

先上方案,再泼盆冷水,①非母语口音问题,官方透露年底将上线多语言支持,首轮拿印度英语开刀②新药上市怎么处理,只需30分钟增量微调,8G显存就能跑起来③GPU要求高不高,单张A10卡即可带动,连老掉牙的服务器都能重新启用,可难题紧随而来中文口音叠加药品新名称,MedASR还能否复现那种离谱级的表现
【行业涟漪】
技术、商业、政策,这三层如同水波一样一起涌动,电子病历厂商已经把API替换周期从12个月缩短到6个月,云厂商连夜整合打包「MedASR+医疗云」套餐,按使用量收费低至0.18美元每小时,监管方更加强势,直接把语音识别写入下一轮合规白名单,要是医疗词错误率低于5%,不要想通过审核。
【未来3问】
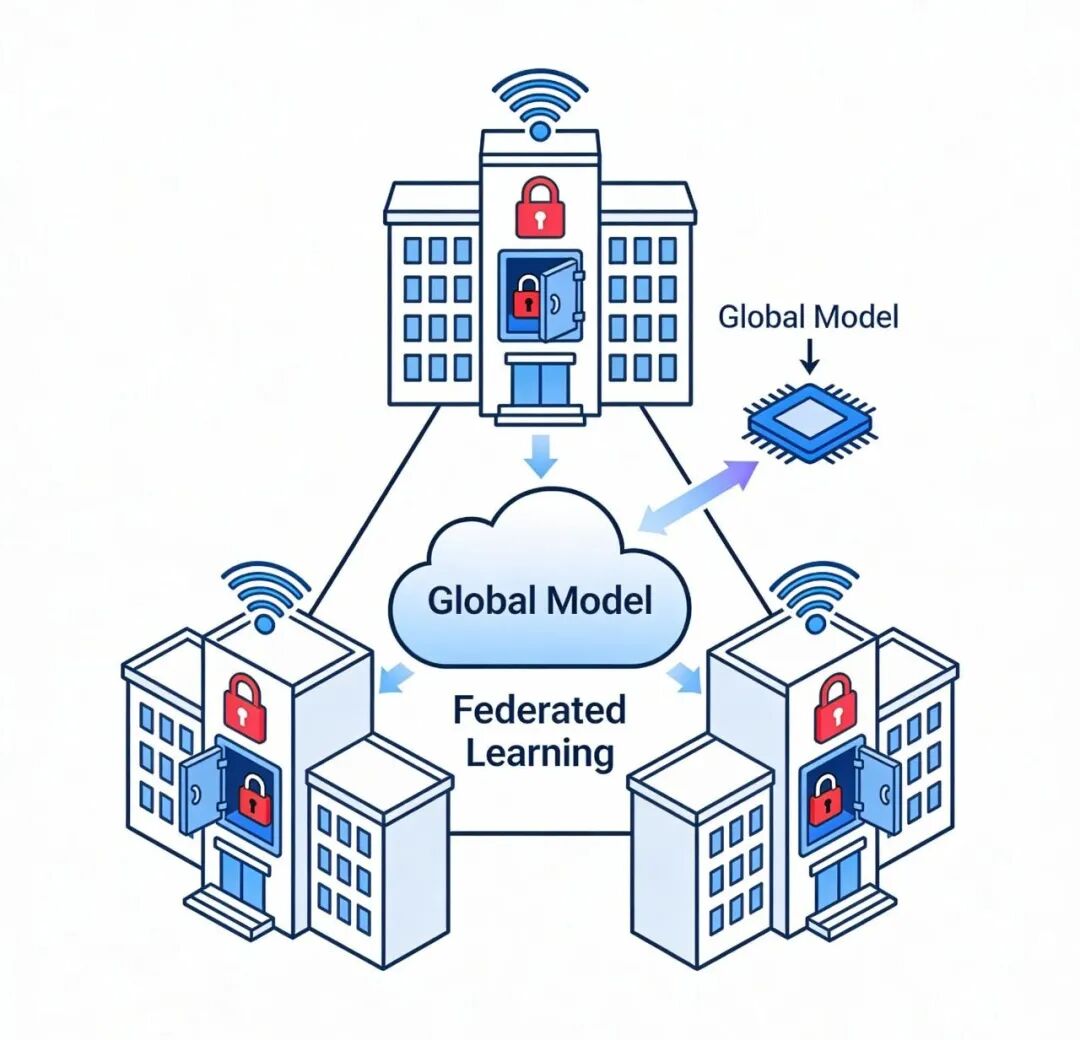
1.多语言版本谁先上线?中日韩药品名混输,模型会不会串味2.并不可以完整地输出ICD-10编码?将肺窗磨玻璃结节直接对应到J98.4,3.本地微调和联邦学习该是怎样的结合,也就是在确保数据不离开医院的同时,还可以共享梯度来进行更新简单来说,医院想要轻易获取别人的药名经验,却不想交出原始病历。
【结尾】
当AI能够准确区分毫克与毫升,医疗,安全才算真正从依赖人眼转向依托机耳,对于通用语音模型而言,只剩一句话可言,打不过,就加入,毕竟,4.6%的词错误率,早已不是地板级,而是地下室级别。
声明:本文内容95%左右为人工手写原创,少部分借助AI辅助,但是所有的内容都是本人经过严格审核和核对的。