
春节临近,DeepSeek-V4的猜测正在AI圈子里发酵。但与其纠结发布日期,不如回溯这家中国AI实验室过去一年留下的技术线索。从DSA到Engram,从mHC到Janus Pro,这些看似晦涩的缩写词,正在拼凑出一幅清晰的画面:当美国同行用更多GPU堆叠参数时,DeepSeek选择了一条更为迂回但精妙的路径,用架构创新挤榨每一个计算单元的极限效率。
这不是第一次有人尝试这条路。许多被搁置的研究方向,在DeepSeek手中重获新生。法国AI研究实验室Pleias联合创始人Alexander Doria将这种策略称为死磕"层效率",让神经网络的每一层都发挥最大价值。而贯穿这一年技术探索的核心主线,就是一个字:稀疏。
记忆、注意力与计算的解耦实验最新公布的Engram模块,瞄准的是Transformer架构的一个根本性浪费。标准的大语言模型本质上是个概率预测机器,它没有真正的"记忆"功能。每次遇到需要回忆事实的问题,比如"埃菲尔铁塔的高度是多少",模型都要动用多层注意力机制和前馈网络进行复杂推理,消耗大量算力去计算那些原本只需要简单查表就能解决的答案。
Engram的设计思路简单粗暴:既然有些知识是固定的,为什么不直接存起来?这个模块通过稀疏查表操作,为固定知识检索静态嵌入,让模型在需要时直接调用,而不是每次都从头推理。DeepSeek团队将这种机制称为"条件记忆",与MoE的"条件计算"形成互补。
实验结果令人振奋。当将约20%到25%的参数预算分配给Engram时,模型性能达到最佳。在相同的激活参数与训练数据条件下,配备Engram的27B参数模型明显优于纯MoE架构的同规模模型。更出乎意料的是,Engram不仅提升了知识密集型任务的表现,在代码推理和数学推理上同样表现出色。
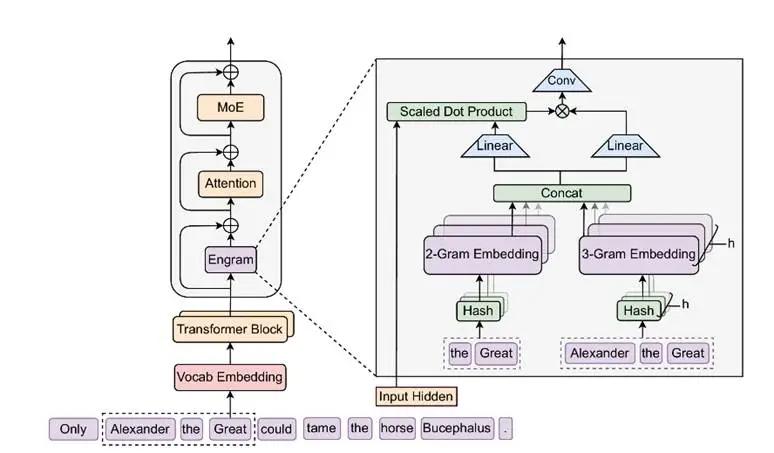
这背后的逻辑很简单:当模型不再把算力浪费在记忆事实上,它就能把更多资源投入到真正需要思考的地方。VentureBeat的报道指出,Engram释放了注意力机制的容量,也提升了长上下文检索能力。对于法律、金融和医疗这些记忆密集型垂直领域而言,这意味着更少的幻觉和更强的推理能力。
从工程角度看,Engram还有个巧妙的设计。频繁访问的内容可以缓存在HBM等高速存储中,而长尾的低频内容则存放在SSD等慢速但大容量的介质里。当团队将1000亿参数的Engram表完全卸载到DRAM时,端到端吞吐量下降不到3%。这有效绕过了GPU的HBM限制,为激进的参数扩展铺平了道路。
不过与RAG不同,Engram仍然是模型内部的参数化记忆,必须参与预训练并直接集成到模型层中。这是"内存"与"计算"的首次真正解耦。
从DSA到mHC的渐进式革新如果把时间线往前推三个月,会看到DeepSeek在跨年期间发布的流形约束超连接。这个名为mHC的技术解决的是深度神经网络训练中的稳定性问题。超级连接本身并非新概念,它能为大模型训练带来接近80%的收敛速度提升,但致命弱点是缺乏扩展稳定性:模型越大、层数越多,训练越容易崩溃。

mHC通过将残差连接投影到低维流形上,确保每一层的计算仍能稳定地转化为有效表示。DeepSeek在论文中称其"为大模型基础架构的演进指明有前景的方向"。有趣的是,这项研究采用了最优传输理论中的Sinkhorn-Knopp算法来施加数学约束,将看似纯粹的工程问题转化为优雅的数学解。
再往前是去年10月推出的上下文光学压缩技术。DeepSeek-OCR模型的核心思路是显著提高信息密度与计算效率,通过逐级压缩信息直至边际遗忘或内化为更深层的表征。团队当时就提出,这一思路"为构建理论上无限上下文长度的模型架构提供了新可能"。
更早期的DSA则探索细粒度稀疏机制。DeepSeek Sparse Attention使用两阶段索引器和top-k选择,将长上下文中的二次复杂度降下来。它能智能过滤噪声,动态选择真正相关的token,大幅降低计算成本的同时几乎不影响输出质量。DeepSeek官方将DSA称为迈向下一代架构的"中间步骤",暗示这些技术最终会整合到V4中。
多模态拼图的最后一块DeepSeek创始人梁文锋曾押注三个方向:代码与数学、多模态、自然语言本身。前两者的进展显而易见,但多模态领域在Janus之后似乎陷入了沉默。
Janus是在2024年末推出的统一多模态理解与生成的自回归框架。这个1.3B参数的模型采用了分离式编码器设计,既能理解图像又能生成图像,突破了以往多模态模型要么只能理解、要么只能生成的局限。2026年1月升级的Janus Pro版本在两个维度上都有显著提升,训练策略、数据质量和模型架构全面优化。
但相比Gemini 3这样的全能型多模态模型,DeepSeek在视频理解、跨模态推理等方面还有差距。Janus Pro会成为V4的核心组件吗?从技术逻辑看,将Engram的条件记忆机制扩展到视觉token并非难事,DSA的稀疏注意力同样适用于处理高分辨率图像或长视频。
算力约束下的创新突围回顾这一年的技术轨迹,会发现一个清晰的模式:DeepSeek总是从数学和工程的双重视角重新审视那些被美国实验室尝试过但未成功的方向。卡西米尔效应启发的记忆稀疏化、最优传输理论支撑的超连接稳定性、细粒度的注意力剪裁,每一项技术单独看都不算革命性创新,但组合起来却形成了一套独特的效率优化体系。
这种策略的背后是中国AI产业面临的现实约束:先进GPU获取受限、算力成本高昂、需要在有限资源下追赶美国同行。但约束也催生了创造力。当OpenAI用10万张H100训练GPT-4时,DeepSeek必须思考如何用更少的卡实现相近的效果。答案不是硬件突破,而是软件层面的精细化设计。
市场对V4的期待不仅是性能指标的提升,更是这套技术路线能否真正缩小中美前沿模型的差距。从目前的技术铺垫看,V4很可能是一个集大成者:Engram提供条件记忆、DSA优化长上下文、mHC保证训练稳定、Janus处理多模态输入。这四块拼图如果能有机整合,或许真能造出一个在中国算力基础设施上高效运行的超大规模模型。
春节后的某个时刻,当V4真正发布时,我们将看到这一年的技术积累最终会凝结成怎样的产品形态。但无论结果如何,DeepSeek已经证明了一件事:在算力竞赛之外,还有另一条通往前沿AI的道路。