在当今这个被数据驱动的时代,我们常常听到一句话:“数据是新的石油”。对于制造业而言,这句话的分量尤为沉重。理论上,工厂的每一台设备、每一次运转、每一个生产环节,都在源源不断地产生数据——这些数据是优化流程、预测故障、提升效率的“原油”。
然而,现实却常常是另一番景象。许多制造企业发现自己陷入了一种尴尬的境地:一方面,他们坐拥海量潜在的数据源;另一方面,却因为技术和认知上的壁垒,无法有效采集、整合和利用这些数据,使得宝贵的“原油”静静地沉睡在机器的轰鸣声中,形成了一片广袤的“数据荒”。
设备老旧、接口各异、协议五花八门,导致数据无法联通 ;ERP、MES、SCADA等系统各自为政,形成了一个个难以逾越的“数据孤岛” ;采集上来的数据质量参差不齐,充满了噪音、错误和延迟,让后续的分析举步维艰 。这些普遍存在的痛点,正是阻碍制造企业从传统生产模式迈向智能制造的“最后一公里”。
那么,如何才能打破僵局,将这片沉睡的“数据荒”转变为一座价值连城的“数据金矿”?答案并非遥不可及,它始于一个坚实的基础——构建一套现代化、体系化的数据采集解决方案。今天,我们将深入探讨,这样一套解决方案如何通过精妙的架构设计和战略性的实施路径,彻底盘活企业的沉睡数据资产。
第一章:破局“数据荒”——现代化数据采集的体系化思考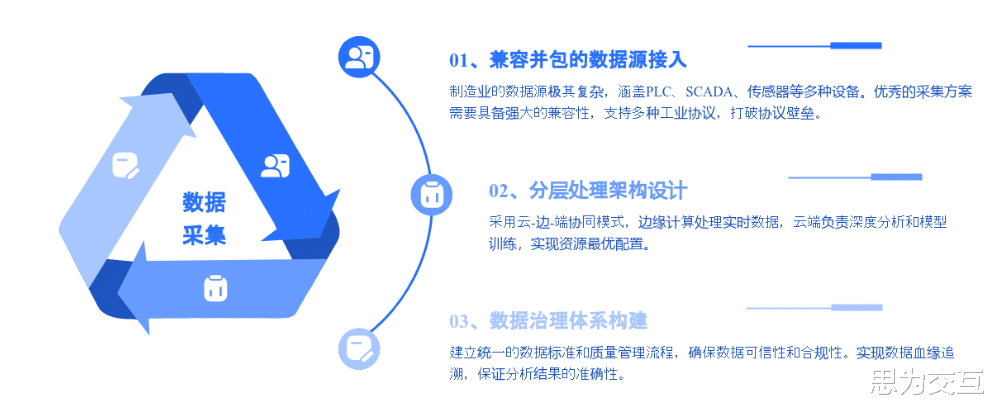
要解决数据采集的难题,绝不能头痛医头、脚痛医脚。它需要一种全局性的、自上而下的体系化思考。一个现代化的数据采集解决方案,其核心并非仅仅是连接几台设备,而是构建一个从物理世界到数字世界的、稳定可靠的数据桥梁。这个桥梁由几个关键部分构成:
1. 坚实的地基:无缝兼容的数据源与采集层
制造业的数据源极其复杂,涵盖了PLC、SCADA、传感器、数控机床以及MES、ERP等各类信息系统 。一个成功的采集方案,首要任务就是具备强大的“兼容并包”能力。它必须能够通过支持OPC-UA、MQTT、Modbus等多种工业协议,适配不同年代、不同厂商的设备,打破协议壁垒,实现对异构数据源的统一接入 。这就像是为数据流动修建了一条多车道、无障碍的高速公路入口,确保任何“车辆”(数据)都能顺畅进入。
2. 智慧的枢纽:从“边缘”到“云端”的分层处理架构
传统的做法是将所有数据一股脑地传送到云端进行处理,但这在工业场景中面临着延迟、带宽和安全三大挑战 。现代架构则采用更为智慧的“云-边-端”协同模式 。
在边缘端(Edge):靠近数据源的地方,部署边缘计算节点。这里的核心任务是“就地解决”。例如,对于需要毫秒级响应的设备状态监测和预警,边缘节点可以实时处理高频振动、温度等数据,进行初步分析和异常检测 。这不仅将响应延迟从云端的数百毫秒降低到边缘的几十毫秒以内 ,还通过数据清洗、过滤和聚合,大幅减少了上传到云端的数据量,有效降低了网络带宽的压力和成本 。
在云端(Cloud):云平台则扮演着“中央大脑”的角色 。它负责接收从各个边缘节点汇聚而来的关键数据,进行大规模的存储、复杂的深度分析、机器学习模型的训练和全局性的业务洞察。例如,通过分析长周期、跨产线的设备数据,云端可以构建出更精准的预测性维护模型,并反过来将优化后的算法部署到边缘节点,形成一个持续学习和优化的闭环 。
这种分层架构,既发挥了边缘计算低延迟、高效率的优势,又利用了云计算强大的存储和计算能力,实现了资源的最优配置。
3. 流动的血脉:确保数据可信的数据治理体系
采集到的数据如果不可信,那么后续的一切分析都将是空中楼阁。因此,在数据采集之初就必须嵌入严格的数据治理框架 。这包括:
统一数据标准:制定企业范围内统一的数据定义、编码规则和格式标准,确保从不同源头采集的数据拥有一致的“语言”,可以被无缝理解和整合 。
强化数据质量管理:建立自动化的数据质量监控流程,对数据的完整性、准确性、一致性和及时性进行持续评估和改进 。例如,通过设定规则自动识别和清洗异常数据,确保流入数据湖的数据是“干净”且可用的。
实现数据血缘追溯:记录数据从产生、采集、处理到应用的完整生命周期轨迹。当分析结果出现偏差时,能够快速追溯到源头,定位问题所在,这对于保证数据的可信度和合规性至关重要 。
一个没有治理的数据采集系统,最终只会制造出一个更大的“数据沼泽”。唯有将治理融入血脉,才能确保流淌在系统中的每一份数据都是高质量、可信赖的资产。
第二章:从蓝图到现实——分阶段实施,让价值“小步快跑”一个宏伟的蓝图固然激动人心,但对于资源有限、风险厌恶的制造企业而言,如何将蓝图稳妥地落地,比蓝图本身更为重要。采用分阶段、迭代式的实施路线图,是确保数据采集项目成功的关键策略。
第一阶段:试点先行,验证价值(Pilot Phase)

与其一上来就追求全面覆盖,不如选择一条关键产线或一组核心设备作为试点 。这个阶段的目标非常明确:用最小的投入,快速验证数据采集方案的技术可行性和业务价值。
关键里程碑:成功连接试点范围内的所有关键设备与系统,实现端到端的数据通路。建立初步的数据看板,将关键性能指标(如OEE、设备利用率)实时可视化。在一个具体的痛点场景(如某个设备的频繁停机问题)上,通过数据分析找到初步的优化方向。
评估标准:技术层面:数据采集的稳定性和实时性是否达标?数据质量是否满足分析要求?业务层面:试点区域的生产效率、设备故障率或产品合格率是否有可量化的初步改善? 是否能计算出一个积极的初步投资回报率(ROI)?
试点的成功,不仅能为项目团队积累宝贵的经验,更能以看得见的成果说服决策层,为后续的全面推广扫清障碍。
第二阶段:标准化推广,扩大战果(Rollout Phase)
在试点成功的基础上,第二阶段的核心任务是将验证过的模式进行标准化和复制推广 。
关键里程碑:将试点中形成的设备接入协议、数据模型、指标计算逻辑固化为标准模板。建立统一的数据治理规范和指标平台,确保跨部门、跨产线的数据口径一致 。将解决方案推广到更多的产线、车间,甚至其他工厂,实现覆盖范围的指数级增长。
评估标准:效率:新产线的接入速度和成本是否显著优于试点阶段?一致性:全公司范围内,对于同一个业务指标(如合格率)的理解和计算方式是否完全统一?协同价值:是否开始出现跨部门数据协同带来的新洞察?例如,将生产数据与能耗数据结合,发现节能降耗的新机会。
第三阶段:深度融合,持续创新(Scale & Innovate Phase)

当数据采集的基础设施全面铺开后,企业才真正拥有了挖掘“数据金矿”的能力。这一阶段的重点是从“数据可见”迈向“数据驱动决策”。
关键里程碑:数据分析应用从简单的报表和监控,深化到预测性维护、工艺参数优化、智能质量检测等高级应用。数据驱动的文化开始在组织内部生根发芽,工程师、管理者习惯于基于数据进行讨论和决策 。形成数据应用创新的正向循环:业务部门提出新问题,数据团队利用现有数据资产快速构建解决方案,方案的成功又反过来激励更多的数据应用探索。
评估标准:业务影响:企业的核心运营指标(如整体设备效率、订单交付周期、单位生产成本)是否因数据驱动的应用而获得持续、显著的改善?创新能力:企业是否能够基于数据资产孵化出新的业务模式或竞争优势?
结语从“数据荒”到“数据矿”的旅程,不是一次简单的技术升级,而是一场深刻的思维变革和管理进化。它始于构建一套强大的数据采集解决方案,但这仅仅是第一步。真正的价值在于,当稳定、可信的数据流开始在企业的血脉中涌动时,它将激活每一个角落的创新潜力。
这条路需要战略性的规划、坚定的投入和持续的努力。但可以肯定的是,今天在数据基础设施上的每一分投资,都将转化为明天在激烈市场竞争中不可撼动的核心竞争力。与其在数据的荒漠中继续等待,不如现在就行动起来,拿起工具,开始挖掘属于您自己的那座“数据金矿”。