DAIR总结本周人工智能Top10论文,主要覆盖10项工作:
1. Lighthouse Attention(Nous Research):一种训练时使用的分层注意力包装器,通过对称压缩QKV实现长上下文预训练加速,训练后移除包装器,推理时仍为标准注意力,带来显著训练提速和更低损失。
2. Is Grep All You Need?:在编码代理中,简单grep文本搜索结合良好代理框架(harness),性能可匹敌或超越嵌入式检索,强调框架设计比检索原语更关键。
3. A Geometric Calculator Inside a Neural Network(Goodfire):在LLM中发现几何计算器,数字以傅里叶特征表示为激活空间中的圆圈,算术操作通过旋转实现,可复用于非数学任务。
4. δ-mem:为冻结的全注意力模型添加紧凑在线关联记忆状态,通过delta-rule更新,提供低秩注意力校正,无需微调即可提升记忆密集任务表现。
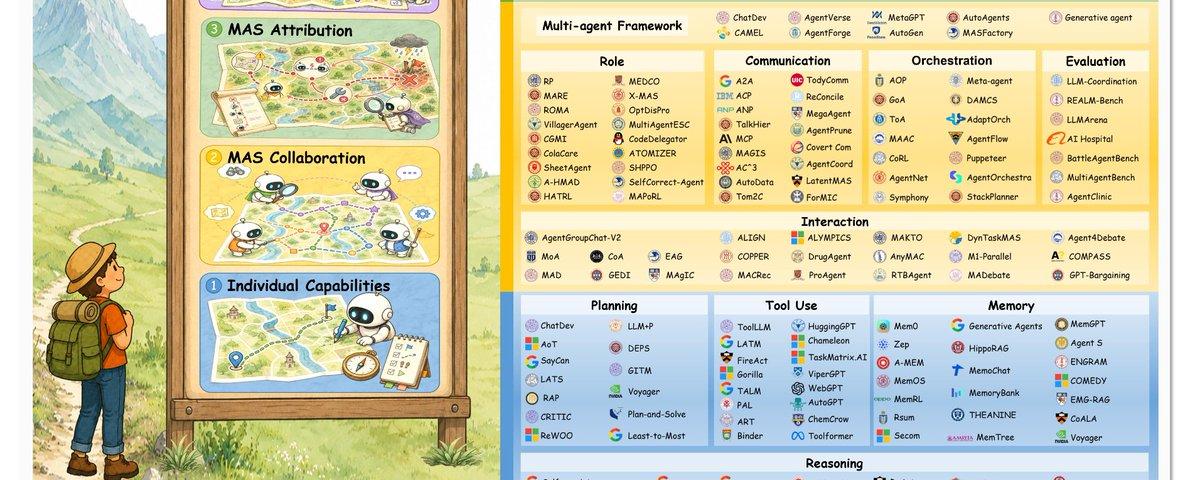
5. Beyond Individual Intelligence:多代理系统综述,沿协作机制、失败归因和自我进化三轴组织,强调系统级演化。
6. AutoTTS:将测试时缩放(TTS)重构为搜索问题,通过发现环境自动搜索策略,成本低且优于手工启发式。
7. AI Co-Mathematician(Google DeepMind):异步状态化数学家工作台,支持并行工作流,在FrontierMath Tier 4上达到48%新高。
8. AEvo:分离候选提议者和元代理角色,利用历史轨迹编辑提议过程,实现代理自我改进。
9. The Memory Curse in LLM Agents:长历史反而侵蚀代理合作意图,主要因前瞻性意图被过去拉扯,可通过干预缓解。
10. Token Superposition Training(Nous Research):修改预训练循环,前1/3阶段处理token包,实现2-3x壁钟加速,最终模型不变。
这一周论文传递的核心洞见是:AI进步正从“参数规模”转向“机制优雅”与“系统智慧”。效率创新降低门槛,可解释性提供控制力,记忆与代理研究解决长期可靠性。这些工作逻辑上互补,形成从预训练到部署的全链路优化。如果持续跟进,我们有望看到更经济、更透明、更具韧性的AI生态。